
Robohub.org
Data-driven deep reinforcement learning
By Aviral Kumar
One of the primary factors behind the success of machine learning approaches in open world settings, such as image recognition and natural language processing, has been the ability of high-capacity deep neural network function approximators to learn generalizable models from large amounts of data. Deep reinforcement learning methods, however, require active online data collection, where the model actively interacts with its environment. This makes such methods hard to scale to complex real-world problems, where active data collection means that large datasets of experience must be collected for every experiment – this can be expensive and, for systems such as autonomous vehicles or robots, potentially unsafe. In a number of domains of practical interest, such as autonomous driving, robotics, and games, there exist plentiful amounts of previously collected interaction data which, consists of informative behaviours that are a rich source of prior information. Deep RL algorithms that can utilize such prior datasets will not only scale to real-world problems, but will also lead to solutions that generalize substantially better. A data-driven paradigm for reinforcement learning will enable us to pre-train and deploy agents capable of sample-efficient learning in the real-world.
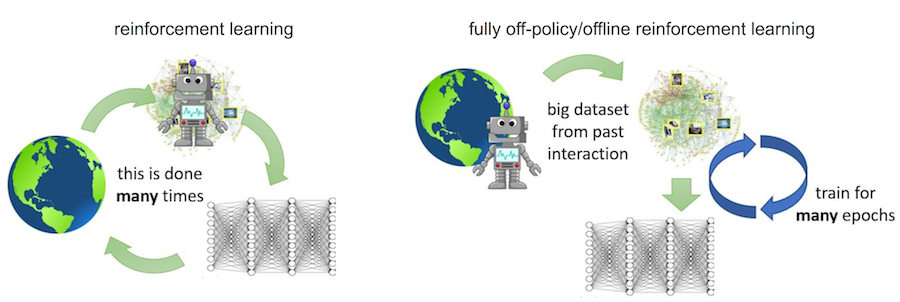
In this work, we ask the following question: Can deep RL algorithms effectively leverage prior collected offline data and learn without interaction with the environment? We refer to this problem statement as fully off-policy RL, previously also called batch RL in literature. A class of deep RL algorithms, known as off-policy RL algorithms can, in principle, learn from previously collected data. Recent off-policy RL algorithms such as Soft Actor-Critic (SAC), QT-Opt, and Rainbow, have demonstrated sample-efficient performance in a number of challenging domains such as robotic manipulation and atari games. However, all of these methods still require online data collection, and their ability to learn from fully off-policy data is limited in practice. In this work, we show why existing deep RL algorithms can fail in the fully off-policy setting. We then propose effective solutions to mitigate these issues.
Why can’t off-policy deep RL algorithms learn from static datasets?
Let’s first study how state-of-the-art deep RL algorithms perform in the fully off-policy setting. We choose the Soft Actor-critic (SAC) algorithm and investigate its performance in the fully off-policy setting. Figure 1 shows the training curve for SAC trained solely on varying amounts of previously collected expert demonstrations for the HalfCheetah-v2 gym benchmark task. Although the data demonstrates successful task completion, none of these runs succeed, with corresponding Q-values diverging in some cases. At first glance, this resembles overfitting, as the evaluation performance deteriorates with more training (green curve), but increasing the size of the static dataset does not rectify the problem (orange (1e4 samples) vs green (1e5 samples)), suggesting the issue is more complex.

Figure 1: Average Return and logarithm of the Q-value for HalfCheetah-v2 with varying amounts of expert data.
Most off-policy RL methods in use today, including SAC used in Figure 1, are based on approximate dynamic programming (though many also utilize importance sampled policy gradients, for example Liu et al. (2019)). The core component of approximate dynamic programming in deep RL is the value function or Q-function. The optimal Q-function obeys the optimal Bellman equation, given below:
Reinforcement learning then corresponds to minimizing the squared difference between the left-hand side and right-hand side of this equation, also referred to as the mean squared Bellman error (MSBE):
MSBE is minimized on transition samples in a dataset generated by a behavior policy . Although minimizing MSBE corresponds to a supervised regression problem, the targets for this regression are themselves derived from the current Q-function estimate.
We can understand the source of the instability shown in Figure 1 by examining the form of the Bellman backup described above. The targets are calculated by maximizing the learned Q-values with respect to the action at the next state () for Q-learning methods, or by computing an expected value under the policy at the next state, for actor-critic methods that maintain an explicit policy alongside a Q-function. However, the Q-function estimator is only reliable on action-inputs from the behavior policy , which is the training distribution. As a result, naively maximizing the value may evaluate the estimator on actions that lie far outside of the training distribution, resulting in pathological values that incur large absolute error from the optimal desired Q-values. We refer to such actions as out-of-distribution (OOD) actions. We call the error in the Q-values caused due to backing up target values corresponding to OOD actions during backups as bootstrapping error. A schematic of this problem is shown in Figure 2 below.

Figure 2: Incorrectly high Q-values for OOD actions may be used for backups, leading to accumulation of error.
Using an incorrect Q-value for computing the backup leads to accumulation of error – minimizing MSBE perfectly leads to propagation of all imperfections in the target values into the current Q-function estimator. We refer to this process as accumulation or propagation of bootstrapping error over iterations of training. The agent is unable to correct errors as it is unable to gather ground truth return information by actively exploring the environment. Accumulation of bootstrapping error can make Q-values diverge to infinity (for example, blue and green curves in Figure 1), or not converge to the correct values (for example, red curve in Figure 1), leading to final performance that is substantially worse than even the average performance in the dataset.
Towards deep RL algorithms that learn in the presence of OOD actions
How can we develop RL algorithms that learn from static data without being affected by OOD actions? We will first review some of the existing approaches in literature towards solving this problem and then describe our recent work, BEAR which tackles this problem. There are broadly two classes of methods towards solving this problem.
Behavioral cloning (BC) based methods: When the static dataset is generated by an expert, one can utilize behavioral cloning to mimic the expert policy, as is done in imitation learning. In a generalized setting, where the behavior policy can be suboptimal but reward information is accessible, one can choose to only mimic a subset of good action decisions from the entire dataset. This is the idea behind prior works such as reward-weighted regression (RWR), relative entropy policy search (REPS), MARWIL, some very recent works such as ABM, and a recent work from our lab, called advantage weighted regression (AWR) where we show that advantage-weighted form of behavioral cloning, which assigns higher likelihoods to demonstration actions that receive higher advantages, can also be used in such situations. Such a method trains only on actions observed in the dataset, hence avoids OOD actions completely.
Dynamic programming (DP) methods: Dynamic programming methods are appealing in fully off-policy RL scenarios because of their ability to pool information across trajectories, unlike BC-based methods that are implicitly constrained to lie in the vicinity of the best performing trajectory in the static dataset. For example, Q-iteration on a dataset consisting of all transitions in an MDP should return the optimal policy at convergence, however previously described BC-based methods may fail to recover optimality if the individual trajectories are highly suboptimal. Within this class, some recent work includes batch constrained Q-learning (BCQ) that constrains the trained policy distribution to lie close to the behavior policy that generated the dataset. This is an optimal strategy when the static dataset is generated by an expert policy. However, this might be suboptimal if the data comes from an arbitrarily suboptimal policy. Other recent work, G-Learning, KL-Control, BRAC implements closeness to the behavior policy by solving a KL-constrained RL problem. SPIBB selectively constrains the learned policy to match the behavior policy in probability density on less frequent actions.
The key question we pose in our work is: Which policies can be reliably used for backups without backing up OOD actions? Once this question is answered, the job of an RL algorithm reduces to picking the best policy in this set. In our work, we provide a theoretical characterization of this set of policies and use insights from theory to propose a practical dynamic programming based deep RL algorithm called BEAR that learns from purely static data.
Bootstrapping Error Accumulation Reduction (BEAR)

Figure 3: Illustration of support constraint (BEAR) (right) and distribution-matching constraint (middle).
The key idea behind BEAR is to constrain the learned policy to lie within the support (Figure 3, right) of the behavior policy distribution. This is in contrast to distribution matching (Figure 3, middle) – BEAR does not constrain the learned policy to be close in distribution to the behavior policy, but only requires that the learned policy places non-zero probability mass on actions with non-negligible behavior policy density. We refer to this as support constraint. As an example, in a setting with a uniform-at-random behavior policy, a support constraint allows dynamic programming to learn an optimal, deterministic policy. However, a distribution-matching constraint will require that the learned policy be highly stochastic (and thus not optimal), for instance in Figure 3, middle, the learned policy is constrained to be one of the stochastic purple policies, however in Figure 3, right, the learned policy can be a (near-)deterministic yellow policy. For the readers interested in theory, the theoretical insight behind this choice is that a support constraint enables us to control error propagation by upper bounding concentrability under the learned policy, while providing the capacity to reduce divergence from the optimal policy.
How do we enforce that the learned policy satisfies the support constraint? In practice, we use the sampled Maximum Mean Discrepancy (MMD) distance between actions as a measure of support divergence. Letting , and $k$ be any RBF kernel, we have:
A simple code snippet for computing MMD is shown below:

is amenable to stochastic gradient-based training and we show that computing using only few samples from both distributions and provides sufficient signal to quantify differences in support but not in probability density, hence making it a preferred measure for implementing the support constraint. To sum up, the new (constrained-)policy improvement step in an actor-critic setup is given by:
Support constraint vs Distribution-matching constraint Some works, for example, KL-Control, BRAC, G-Learning, argue that using a distribution-matching constraint might suffice in such fully off-policy RL problems. In this section, we take a slight detour towards analyzing this choice. In particular, we provide an instance of an MDP where distribution-matching constraint might lead to arbitrarily suboptimal behavior while support matching does not suffer from this issue.
Consider the 1D-lineworld MDP shown in Figure 4 below. Two actions (left and right) are available to the agent at each state. The agent is tasked with reaching to the goal state , starting from state and the corresponding per-step reward values are shown in Figure 4(a). The agent is only allowed to learn from behavior data generated by a policy that performs actions with probabilities described in Figure 4(b), and in particular, this behavior policy executes the suboptimal action at states in-between S and G with a high likelihood of 0.9, however, both actions and are in-distribution at all these states.

Figure 4: Example 1D lineworld and the corresponding behavior policy.
In Figure 5(a), we show that the learned policy with a distribution-matching constraint can be arbitrarily suboptimal, infact, the probability of reaching goal G by rolling out this policy is very small, and tends to 0 as the environment is made larger. However, in Figure 5(b), we show that a support constraint can recover an optimal policy with probability 1.

Figure 5: Policies learned via distribution-matching and support-matching in the 1D lineworld shown in Figure 4.
Why does distribution-matching fail here? Let us analyze the case when we use a penalty for distribution-matching. If the penalty is enforced tightly, then the agent will be forced to mainly execute the wrong action () in states between and , leading to suboptimal behavior. However, if the penalty is not enforced tightly, with the intention of achieving a better policy than the behavior policy, the agent will perform backups using the OOD-action at states to the left of , and these backups will eventually affect the Q-value at state . This phenomenon will lead to an incorrect Q-function, and hence a wrong policy – possibly, one that goes to the left starting from instead of moving towards , as OOD-action backups combined with overestimation bias in Q-learning might make action at state look more preferable. Figure 6 shows that some states need a strong penalty/constraint (to prevent OOD backups) and the others require a weak penalty/constraint (to achieve optimality) for distribution-matching to work, however, this cannot be achieved via conventional distribution-matching approaches.

Figure 6: Analysis of the strength of distribution-matching constraint needed at different states.
So, how does BEAR perform in practice?
In our experiments, we evaluated BEAR on three kinds of datasets generated by – (1) a partially-trained medium-return policy, (2) a random low-return policy and (3) an expert, high-return policy. (1) resembles the settings in practice such as autonomous driving or robotics, where offline data is collected via scripted policies for robotic grasping or consists of human driving data (which may not be perfect) respectively. Such data is useful as it demonstrates non-random, but still not optimal behavior and we expect training on offline data to be most useful in this setting. Good performance on both (2) and (3) demonstrates that the versatility of an algorithm to arbitrary dataset compositions.
For each dataset composition, we compare BEAR to a number of baselines including BC, BCQ, and deep Q-Learning from demonstrations (DQfD). In general, we find that BEAR outperforms the best performing baseline in setting (1), and BEAR is the only algorithm capable successfully learning a better-than-dataset policy in both (2) and (3). We show some learning curves below. BC or BCQ type methods usually do not perform great with random data, partly because of the usage of a distribution-matching constraint as described earlier.

Figure 7: Performance on (1) medium-quality dataset: BEAR outperforms the best performing baseline.

Figure 8: (3) Expert data: BEAR recovers the performance in the expert dataset, and performs similarly to other methods such as BC.

Figure 9: (2) Random data: BEAR recovers better than dataset performance, and is close to the best performing algorithm (Naive RL).
Future Directions and Open Problems
Most of the prior datasets for real-world problems such as RoboNet and Starcraft replays consist of multimodal behavior generated by different users and robots. Hence, one of the next steps to look at is learning from a diverse mixtures of policies. How can we effectively learn policies from a static dataset that consists of a diverse range of behavior – possibly interaction from a diverse range of tasks, in the spirit of what we encounter in the real world? This question is mostly unanswered at the moment. Some very recent work, such as REM, shows that simple modifications to existing distributional off-policy RL algorithms in the Atari domain can enable fully off-policy learning on entire interaction data generated from the training run of a separate DQN agent. However, the best solution for learning from a dataset generated by any arbitrary mixture of policies – which is more likely the case in practical problems – is unclear.
A rigorous theoretical characterization of the best achievable policy as a function of a given dataset is also an open problem. In our paper, we analyze this question by looking at typically used assumptions of bounded concentrability in the error and convergence analysis of Fitted Q-iteration. Which other assumptions can be applied to analyze this problem? And which of these assumptions is least restrictive and practically feasible? What is the theoretical optimum of what can be achieved solely by offline training?
We hope that our work, BEAR, takes us a step closer to effectively leveraging the most out of prior datasets in an RL algorithm. A data-driven paradigm of RL where one could (pre-)train RL algorithms with large amounts of prior data will enable us to go beyond the active exploration bottleneck, thus giving us agents that can be deployed and keep learning continuously in the real world.
This blog post is based on the our recent paper:
- Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction
Aviral Kumar*, Justin Fu*, George Tucker, Sergey Levine
In Advances in Neural Information Processing Systems, 2019
The paper and code are available online and a slide-deck explaining the algorithm is available here. I would like to thank Sergey Levine for his valuable feedback on earlier versions of this blog post. This article was initially published on the BAIR blog, and appears here with the authors’ permission.

AUAI is supported by:









