
Robohub.org
Dexterous manipulation with reinforcement learning: Efficient, general, and low-cost

In this post, we demonstrate how deep reinforcement learning (deep RL) can be used to learn how to control dexterous hands for a variety of manipulation tasks. We discuss how such methods can learn to make use of low-cost hardware, can be implemented efficiently, and how they can be complemented with techniques such as demonstrations and simulation to accelerate learning.
Why Dexterous Hands?
A majority of robots in use today use simple parallel jaw grippers as manipulators, which are sufficient for structured settings like factories. However, manipulators that are capable of performing a wide array of tasks are essential for unstructured human-centric environments like the home. Multi-fingered hands are among the most versatile manipulators, and enable a wide variety of skills we use in our everyday life such as moving objects, opening doors, typing, and painting.

Unfortunately, controlling dexterous hands is extremely difficult, which limits their use. High-end hands can also be extremely expensive, due to delicate sensing and actuation. Deep reinforcement learning offers the promise of automating complex control tasks even with cheap hardware, but many applications of deep RL use huge amounts of simulated data, making them expensive to deploy in terms of both cost and engineering effort. Humans can learn motor skills efficiently, without a simulator and millions of simulations.
We will first show that deep RL can in fact be used to learn complex manipulation behaviors by training directly in the real world, with modest computation and low-cost robotic hardware, and without any model or simulator. We then describe how learning can be further accelerated by incorporating additional sources of supervision, including demonstrations and simulation. We demonstrate learning on two separate hardware platforms: an inexpensive custom-built 3-fingered hand (the Dynamixel Claw), which costs under \$2500, and the higher-end Allegro hand, which costs about \$15,000.

Left: Dynamixel Claw. Right: Allegro Hand.
Model-free Reinforcement Learning in the Real World
Deep RL algorithms learn by trial and error, maximizing a user-specified reward function from experience. We’ll use a valve rotation task as a working example, where the hand must open a valve or faucet by rotating it 180 degrees.

Illustration of valve rotation task.
The reward function simply consists of the negative distance between the current and desired valve orientation, and the hand must figure out on its own how to move to rotate it. A central challenge in deep RL is in using this weak reward signal to find a complex and coordinated behavior strategy (a policy) that succeeds at the task. The policy is represented by a multilayer neural network. This typically requires a large number of trials, so much so that the community is split on whether deep RL methods can be used for training outside of simulation. However, this imposes major limitations on their applicability: learning directly in the real world makes it possible to learn any task from experience, while using simulators requires designing a suitable simulation, modeling the task and the robot, and carefully adjusting their parameters to achieve good results. We will show later that simulation can accelerate learning substantially, but we first demonstrate that existing RL algorithms can in fact learn this task directly on real hardware.
A variety of algorithms should be suitable. We use Truncated Natural Policy Gradient to learn the task, which requires about 9 hours on real hardware.


Learning progress of the dynamixel claw on valve rotation.

Final Trained Policy on valve rotation.
The direct RL approach is appealing for a number of reasons. It requires minimal assumptions, and is thus well suited to autonomously acquire a large repertoire of skills. Since this approach assumes no information other than access to a reward function, it is easy to relearn the skill in a modified environment, for example when using a different object or a different hand – in this case, the Allegro hand.

360° valve rotation with Allegro Hand.
The same exact method can learn to rotate the valve when we use a different material. We can learn how to rotate a valve made out of foam. This can be quite difficult to simulate accurately, and training directly in the real world allows us to learn without needing accurate simulations.

Dynamixel claw rotating a foam screw.
The same approach takes 8 hours to solve a different task, which requires flipping an object 180 degrees around the horizontal axis, without any modification.


Dynamixel claw flipping a block.
These behaviors were learned with low cost hardware (<\$2500) and a single consumer desktop computer.
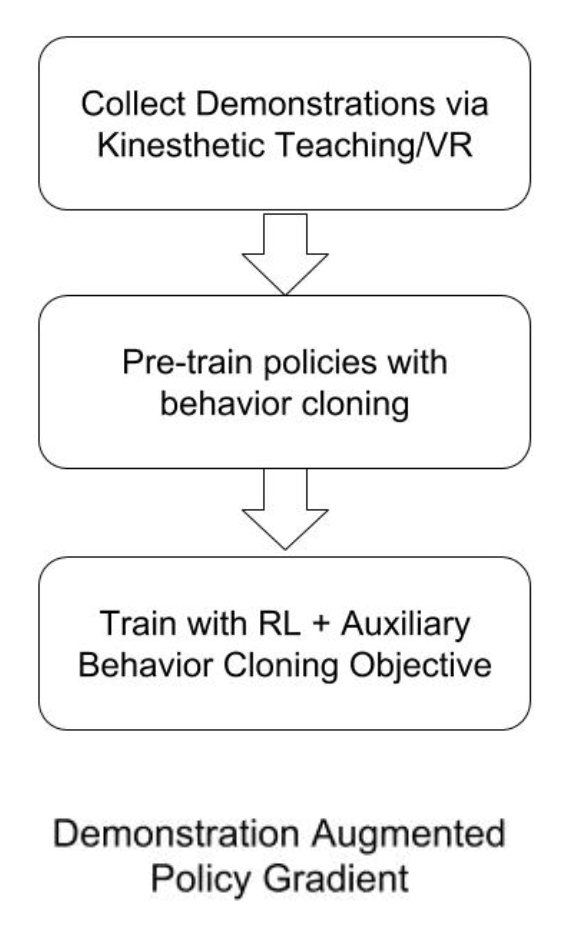
Accelerating Learning with Human Demonstrations
While model-free RL is extremely general, incorporating supervision from human experts can help accelerate learning further. One way to do this, which we describe in our paper on Demonstration Augmented Policy Gradient (DAPG), is to incorporate human demonstrations into the reinforcement learning process. Related approaches have been proposed in the context of off-policy RL, Q-learning, and other robotic tasks. The key idea behind DAPG is that demonstrations can be used to accelerate RL in two ways
-
Provide a good initialization for the policy via behavior cloning.
-
Provide an auxiliary learning signal throughout the learning process to guide exploration using a trajectory tracking auxiliary reward.
The auxiliary objective during RL prevents the policy from diverging from the demonstrations during the RL process. Pure behavior cloning with limited data is often ineffective in training successful policies due to distribution drift and limited data support. RL is crucial for robustness and generalization and use of demonstrations can substantially accelerate the learning process. We previously validated this algorithm in simulation on a variety of tasks, shown below, where each task used only 25 human demonstrations collected in virtual reality. DAPG enables a speedup of up to 30x on these tasks, while also learning natural and robust behaviors.




Behaviors learned in simulation with DAPG: object pickup, tool use, in-hand, door opening.



Behaviors robust to size and shape variations; natural and smooth behavior.
In the real world, we can use this algorithm with the dynamixel claw to significantly accelerate learning. The demonstrations are collected with kinesthetic teaching, where a human teacher moves the fingers of the robots directly in the real world. This brings down the training time on both tasks to under 4 hours.


Left: Valve rotation policy with DAPG. Right: Flipping policy with DAPG.
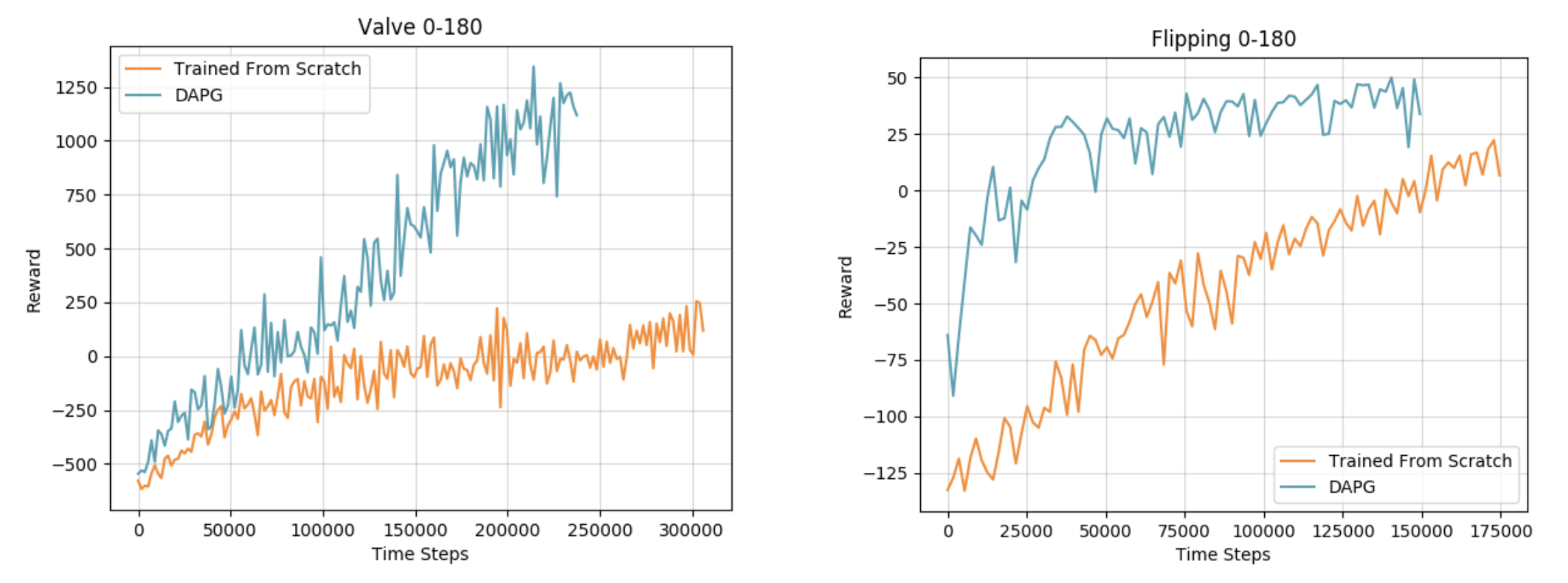
Learning Curves of RL from scratch on hardware vs DAPG.
Demonstrations provide a natural way to incorporate human priors and accelerate the learning process. Where high quality successful demonstrations are available, augmenting RL with demonstrations has the potential to substantially accelerate RL. However, obtaining demonstrations may not be possible for all tasks or robot morphologies, necessitating the need to also pursue alternate acceleration schemes.
Accelerating Learning with Simulation
A simulated model of the task can help augment the real world data with large amounts of simulated data to accelerate the learning process. For the simulated data to be representative of the complexities of the real world, randomization of various simulation parameters is often necessitated. This kind of randomization has previously been observed to produce robust policies, and can facilitate transfer in the face of both visual and physical discrepancies. Our experiments also suggest that simulation to reality transfer with randomization can be effective.

Policy for valve rotation transferred from simulation using randomization.
Transfer from simulation has also been explored in concurrent work for dexterous manipulation to learn impressive behaviors, and in a number of prior works for tasks such as picking and placing, visual servoing, and locomotion. While simulation to real transfer enabled by randomization is an appealing option, especially for fragile robots, it has a number of limitations. First, the resulting policies can end up being overly conservative due to the randomization, a phenomenon that has been widely observed in the field of robust control. Second, the particular choice of parameters to randomize is crucial for good results, and insights from one task or problem domain may not transfer to others. Third, increasing the amount of randomization results in more complex models tremendously increasing the training time and required computational resources (Andrychowicz et al report 100 years of simulated experience, training in 50 hours on thousands of CPU cores). Directly training in the real world may be more efficient and lead to better policies. Finally, and perhaps most importantly, an accurate simulator must be constructed manually, with each new task modeled by hand in the simulation, which requires substantial time and expertise. However, leveraging simulations appropriately can accelerate the learning, and more systematic transfer methods are an important direction for future work.
Accelerating Learning with Learned Models
In some of our previous work, we also studied how learned dynamics models can accelerate real-world reinforcement learning without access to manually engineered simulators. In this approach, local derivatives of the dynamics are approximated by fitting time-varying linear systems, which can then be used to locally and iterative improve a policy. This approach can acquire a variety of in-hand manipulation strategies from scratch in the real world. Furthermore, we see that the same algorithm can even learn to control a pneumatic soft robotic hand to perform a number of dexterous behaviors


Left: Adroit robotic hand performing in-hand manipulation. Right: Pneumatic Soft RBO Hand performing dexterous tasks.
However, the performance of methods with learned models is limited by the quality of the model that can be learned, and in practice asymptotic performance is often still higher with the best model-free algorithms. Further study of model-based reinforcement learning for efficient and effective real-world learning is a promising research direction.
Takeaways and Challenges
While training in the real world is general and broadly applicable, it has several challenges of its own.
-
Due to the requirement to take a large number of exploratory actions, we observed that the hands often heat up quickly, which requires pauses to avoid damage.
-
Since the hands must attempt the task multiple times, we had to build an automatic reset mechanism. In the future, a promising direction to remove this requirement is to automatically learn reset policies.
-
Reinforcement learning methods require rewards to be provided, and this reward must still be designed manually. Some of our recent work has looked at automating reward specification.
However, enabling robots to learn complex skills directly in the real world is one of the best paths forward to developing truly generalist robots. In the same way that humans can learn directly from experience in the real world, robots that can acquire skills simply by trial and error can explore novel solutions to difficult manipulation problems and discover them with minimal human intervention. At the same time, the availability of demonstrations, simulators, and other prior knowledge can further reduce training times.
This article was initially published on the BAIR blog, and appears here with the authors’ permission. The work in this post is based on these papers:
- Optimal control with learned local models: Application to dexterous manipulation
- Learning Dexterous Manipulation for a Soft Robotic Hand from Human Demonstration
- Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
A complete paper on the new robotic experiments will be released soon. The research was conducted by Henry Zhu, Abhishek Gupta, Vikash Kumar, Aravind Rajeswaran, and Sergey Levine. Collaborators on earlier projects include Emo Todorov, John Schulman, Giulia Vezzani, Pieter Abbeel, Clemens Eppner.

AUAI is supported by:









