
Robohub.org
#IJCAI2025 distinguished paper: Combining MORL with restraining bolts to learn normative behaviour
 Image provided by the authors – generated using Gemini.
Image provided by the authors – generated using Gemini.
For many of us, artificial intelligence (AI) has become part of everyday life, and the rate at which we assign previously human roles to AI systems shows no signs of slowing down. AI systems are the crucial ingredients of many technologies — e.g., self-driving cars, smart urban planning, digital assistants — across a growing number of domains. At the core of many of these technologies are autonomous agents — systems designed to act on behalf of humans and make decisions without direct supervision. In order to act effectively in the real world, these agents must be capable of carrying out a wide range of tasks despite possibly unpredictable environmental conditions, which often requires some form of machine learning (ML) for achieving adaptive behaviour.
Reinforcement learning (RL) [6] stands out as a powerful ML technique for training agents to achieve optimal behaviour in stochastic environments. RL agents learn by interacting with their environment: for every action they take, they receive context-specific rewards or penalties. Over time, they learn behaviour that maximizes the expected rewards throughout their runtime.
Image provided by the authors – generated using Gemini.
RL agents can master a wide variety of complex tasks, from winning video games to controlling cyber-physical systems such as self-driving cars, often surpassing what expert humans are capable of. This optimal, efficient behaviour, however, if left entirely unconstrained, may turn out to be off-putting or even dangerous to the humans it impacts. This motivates the substantial research effort in safe RL, where specialized techniques are developed to ensure that RL agents meet specific safety requirements. These requirements are often expressed in formal languages like linear temporal logic (LTL), which extends classical (true/false) logic with temporal operators, allowing us to specify conditions like “something that must always hold”, or “something that must eventually occur”. By combining the adaptability of ML with the precision of logic, researchers have developed powerful methods for training agents to act both effectively and safely.
However, safety isn’t everything. Indeed, as RL-based agents are increasingly given roles that either replace or closely interact with humans, a new challenge arises: ensuring their behavior is also compliant with the social, legal and ethical norms that structure human society, which often go beyond simple constraints guaranteeing safety. For example, a self-driving car might perfectly follow safety constraints (e.g. avoiding collisions), yet still adopt behaviors that, while technically safe, violate social norms, appearing bizarre or rude on the road, which might cause other (human) drivers to react in unsafe ways.
Norms are typically expressed as obligations (“you must do it”), permissions (“you are permitted to do it”) and prohibitions (“you are forbidden from doing it”), which are not statements that can be true or false, like classical logic formulas. Instead, they are deontic concepts: they describe what is right, wrong, or permissible — ideal or acceptable behaviour, instead of what is actually the case. This nuance introduces several difficult dynamics to reasoning about norms, which many logics (such as LTL) struggle to handle. Even every-day normative systems like driving regulations can feature such complications; while some norms can be very simple (e.g., never exceed 50 kph within city limits), others can be more complex, as in:
- Always maintain 10 meters between your vehicle and the vehicles in front of and behind you.
- If there are less than 10 meters between you and the vehicle behind you, you should slow down to put more space between yourself and the vehicle in front of you.
(2) is an example of a contrary-to-duty obligation (CTD), an obligation you must follow specifically in a situation where another primary obligation (1) has already been violated to, e.g., compensate or reduce damage. Although studied extensively in the fields of normative reasoning and deontic logic, such norms can be problematic for many basic safe RL methods based on enforcing LTL constraints, as was discussed in [4].
However, there are approaches for safe RL that show more potential. One notable example is the Restraining Bolt technique, introduced by De Giacomo et al. [2]. Named after a device used in the Star Wars universe to curb the behavior of droids, this method influences an agent’s actions to align with specified rules while still allowing it to pursue its goals. That is, the restraining bolt modifies the behavior an RL agent learns so that it also respects a set of specifications. These specifications, expressed in a variant of LTL (LTLf [3]), are each paired with its own reward. The central idea is simple but powerful: along with the rewards the agent receives while exploring the environment, we add an additional reward whenever its actions satisfy the corresponding specification, nudging it to behave in ways that align with individual safety requirements. The assignment of specific rewards to individual specifications allows us to model more complicated dynamics like, e.g., CTD obligations, by assigning one reward for obeying the primary obligation, and a different reward for obeying the CTD obligation.
Still, issues with modeling norms persist; for example, many (if not most) norms are conditional. Consider the obligation stating “if pedestrians are present at a pedestrian crossing, THEN the nearby vehicles must stop”. If an agent were rewarded every time this rule was satisfied, it would also receive rewards in situations where the norm is not actually in force. This is because, in logic, an implication holds also when the antecedent (“pedestrians are present”) is false. As a result, the agent is rewarded whenever pedestrians are not around, and might learn to prolong its runtime in order to accumulate these rewards for effectively doing nothing, instead of efficiently pursuing its intended task (e.g., reaching a destination). In [5] we showed that there are scenarios where an agent will either ignore the norms, or learn this “procrastination” behavior, no matter which rewards we choose. As a result, we introduced Normative Restraining Bolts (NRBs), a step forward toward enforcing norms in RL agents. Unlike the original Restraining Bolt, which encouraged compliance by providing additional rewards, the normative version instead punishes norm violations. This design is inspired by the Andersonian view of deontic logic [1], which treats obligations as rules whose violation necessarily triggers a sanction. Thus, the framework no longer relies on reinforcing acceptable behavior, but instead enforces norms by guaranteeing that violations carry tangible penalties. While effective for managing intricate normative dynamics like conditional obligations, contrary-to-duties, and exceptions to norms, NRBs rely on trial-and-error reward tuning to implement norm adherence, and therefore can be unwieldy, especially when trying to resolve conflicts between norms. Moreover, they require retraining to accommodate norm updates, and do not lend themselves to guarantees that optimal policies minimize norm violations.
Our contribution
Building on NRBs, we introduce Ordered Normative Restraining Bolts (ONRBs), a framework for guiding reinforcement learning agents to comply with social, legal, and ethical norms while addressing the limitations of NRBs. In this approach, each norm is treated as an objective in a multi-objective reinforcement learning (MORL) problem. Reformulating the problem in this way allows us to:
- Prove that when norms do not conflict, an agent who learns optimal behaviour will minimize norm violations over time.
- Express relationships between norms in terms of a ranking system describing which norm should be prioritized when a conflict occurs.
- Use MORL techniques to algorithmically determine the necessary magnitude of the punishments we assign such that it is guarantied that so long as an agent learns optimal behaviour, norms will be violated as little as possible, prioritizing the norms with the highest rank.
- Accommodate changes in our normative systems by “deactivating” or “reactivating” specific norms.
We tested our framework in a grid-world environment inspired by strategy games, where an agent learns to collect resources and deliver them to designated areas. This setup allows us to demonstrate the framework’s ability to handle the complex normative scenarios we noted above, along with direct prioritization of conflicting norms and norm updates. For instance, the figure below
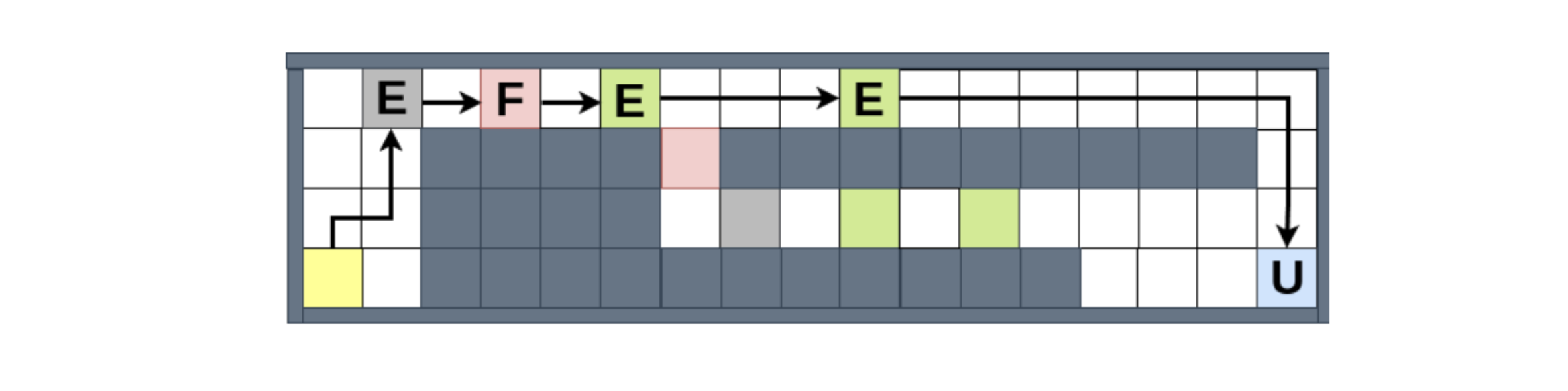
displays how the agent handles norm conflicts, when it is both obligated to (1) avoid the dangerous (pink) areas, and (2) reach the market (blue) area by a certain deadline, supposing that the second norm takes priority. We can see that it chooses to violate (1) once, because otherwise it will be stuck at the beginning of the map, unable to fulfill (2). Nevertheless, when given the possibility to violate (1) once more, it chooses the compliant path, even though the violating path would allow it to collect more resources, and therefore more rewards from the environment.
In summary, by combining RL with logic, we can build AI agents that do not just work, they work right.
This work won a distinguished paper award at IJCAI 2025. Read the paper in full: Combining MORL with restraining bolts to learn normative behaviour, Emery A. Neufeld, Agata Ciabattoni and Radu Florin Tulcan.
Acknowledgements
This research was funded by the Vienna Science and Technology Fund (WWTF) project ICT22-023 and the Austrian Science Fund (FWF) 10.55776/COE12 Cluster of Excellence Bilateral AI.
References
[1] Alan Ross Anderson. A reduction of deontic logic to alethic modal logic. Mind, 67(265):100–103, 1958.
[2] Giuseppe De Giacomo, Luca Iocchi, Marco Favorito, and Fabio Patrizi. Foundations for restraining bolts: Reinforcement learning with LTLf/LDLf restraining specifications. In Proceedings of the international conference on automated planning and scheduling, volume 29, pages 128–136, 2019.
[3] Giuseppe De Giacomo and Moshe Y Vardi. Linear temporal logic and linear dynamic logic on finite traces. In IJCAI, volume 13, pages 854–860, 2013.
[4] Emery Neufeld, Ezio Bartocci, and Agata Ciabattoni. On normative reinforcement learning via safe reinforcement learning. In PRIMA 2022, 2022.
[5] Emery A Neufeld, Agata Ciabattoni, and Radu Florin Tulcan. Norm compliance in reinforcement learning agents via restraining bolts. In Legal Knowledge and Information Systems JURIX 2024, pages 119–130. IOS Press, 2024.
[6] Richard S. Sutton and Andrew G. Barto. Reinforcement learning – an introduction. Adaptive computation and machine learning. MIT Press, 1998.





