
Robohub.org
One-shot imitation from watching videos
By Tianhe Yu and Chelsea Finn
Learning a new skill by observing another individual, the ability to imitate, is a key part of intelligence in human and animals. Can we enable a robot to do the same, learning to manipulate a new object by simply watching a human manipulating the object just as in the video below?


The robot learns to place the peach into the red bowl after watching the human do so.
Such a capability would make it dramatically easier for us to communicate new goals to robots – we could simply show robots what we want them to do, rather than teleoperating the robot or engineering a reward function (an approach that is difficult as it requires a full-fledged perception system). Many prior works have investigated how well a robot can learn from an expert of its own kind (i.e. through teleoperation or kinesthetic teaching), which is usually called imitation learning. However, imitation learning of vision-based skills usually requires a huge number of demonstrations of an expert performing a skill. For example, a task like reaching toward a single fixed object using raw pixel input requires 200 demonstrations to achieve good performance according to this prior work. Hence a robot will struggle if there’s only one demonstration presented.
Moreover, the problem becomes even more challenging when the robot needs to imitate a human showing a certain manipulation skill. First, the robot arm looks significantly different from the human arm. Second, engineering the right correspondence between human demonstrations and robot demonstrations is unfortunately extremely difficult. It’s not enough simple to track and remap the motion: the task depends much more critically on how this motion affects objects in the world, and we need a correspondence that is centrally based on the interaction.
To enable the robot to imitate skills from one video of a human, we can allow it to incorporate prior experience, rather than learn each skill completely from scratch. By incorporating prior experience, the robot should also be able to quickly learn to manipulate new objects while being invariant to shifts in domain, such as a person providing a demonstration, a varying background scene, or different viewpoint. We aim to achieve both of these abilities, few-shot imitation and domain invariance, by learning to learn from demonstration data. The technique, also called meta-learning and discussed in this previous blog post, is the key to how we equip robots with the ability to imitate by observing a human.
One-Shot Imitation Learning
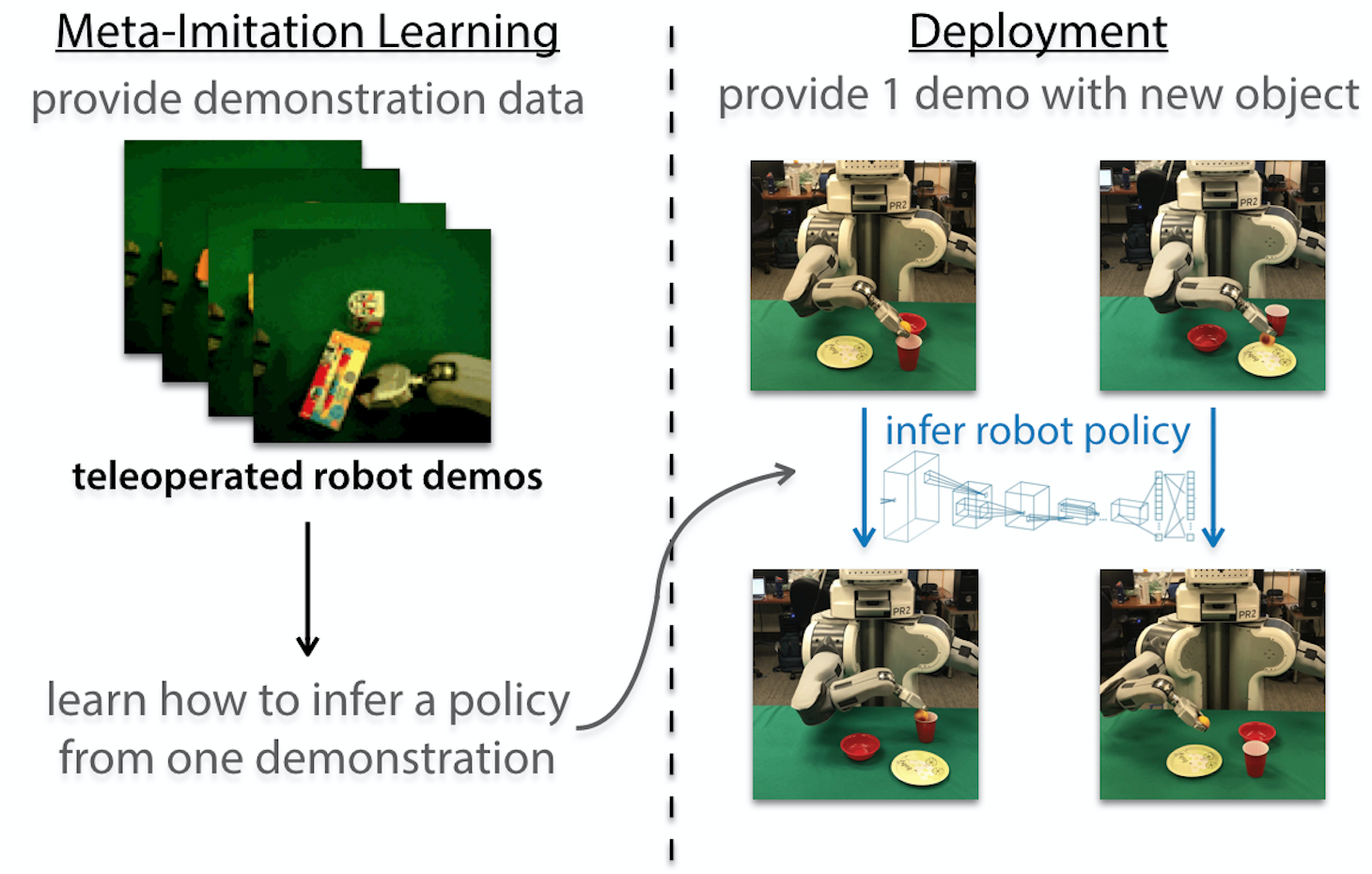
So how can we use meta-learning to make a robot quickly adapt to many different objects? Our approach is to combine meta-learning with imitation learning to enable one-shot imitation learning. The core idea is that provided a single demonstration of a particular task, i.e. maneuvering a certain object, the robot can quickly identify what the task is and successfully solve it under different circumstances. A prior work on one-shot imitation learning achieves impressive results on simulated tasks such as block-stacking by learning to learn across tens of thousands of demonstrations. If we want a physical robot to able to emulate humans and manipulate a variety of novel objects, we need to develop a new system that can learn to learn from demonstrations in the form of videos using a dataset that can be practically collected in the real world. First, we’ll discuss our approach for visual imitation of a single demonstration collected via teleoperation. Then, we’ll show how it can be extended for learning from videos of humans.
One-Shot Visual Imitation Learning
In order to make robots able to learn from watching videos, we combine imitation learning with an efficient meta-learning algorithm, model-agnostic meta-learning (MAML). This previous blog post gives a nice overview of the MAML algorithm. In this approach, we use a standard convolutional neural network with parameters $\theta$ as our policy representation, mapping from an image $o_t$ from the robot’s camera and the robot configuration $x_t$ (e.g. joint angles and joint velocities) to robot actions $a_t$ (e.g. the linear and angular velocity of the gripper) at time step $t$.
There are three main steps in this algorithm.
Three steps for our meta-learning algorithm.
First, we collected a large dataset containing demonstrations of a teleoperated robot performing many different tasks, which in our case, corresponds to manipulating different objects. During the second step, we use MAML to learn an initial set of policy parameters $\theta$, such that, after being provided a demonstration for a certain object, we can run gradient descent with respect to the demonstration to find a generalizable policy with parameters $\theta’$ for that object. When using teleoperated demonstrations, the policy updates can be computed by comparing the policy’s predicted action $\pi_\theta(o_t)$ to the expert action :
Then, we optimize for the initial parameters $\theta$ by driving the updated policy to match the actions from another demonstration with the same object. After meta-training, we can ask the robot to manipulate completely unseen objects by computing gradient steps using a single demonstration of that task. This step is called meta-testing.
As the method does not introduce any additional parameters for meta-learning and optimization, it turns out to be quite data-efficient. Hence it can perform various control tasks such as pushing and placing by just watching a teleoperated robot demonstration:


Placing items into novel containers using a single demonstration. Left: demo. Right: learned policy.
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
The above method still relies on demonstrations coming from a teleoperated robot rather than a human. To this end, we designed a domain-adaptive one-shot imitation approach building on the above algorithm. We collected demonstrations of many different tasks performed by both teleoperated robots and humans. Then, we provide the human demonstration for computing the policy update and evaluate the updated policy using a robot demonstration performing the same task. A diagram illustrating this algorithm is below:
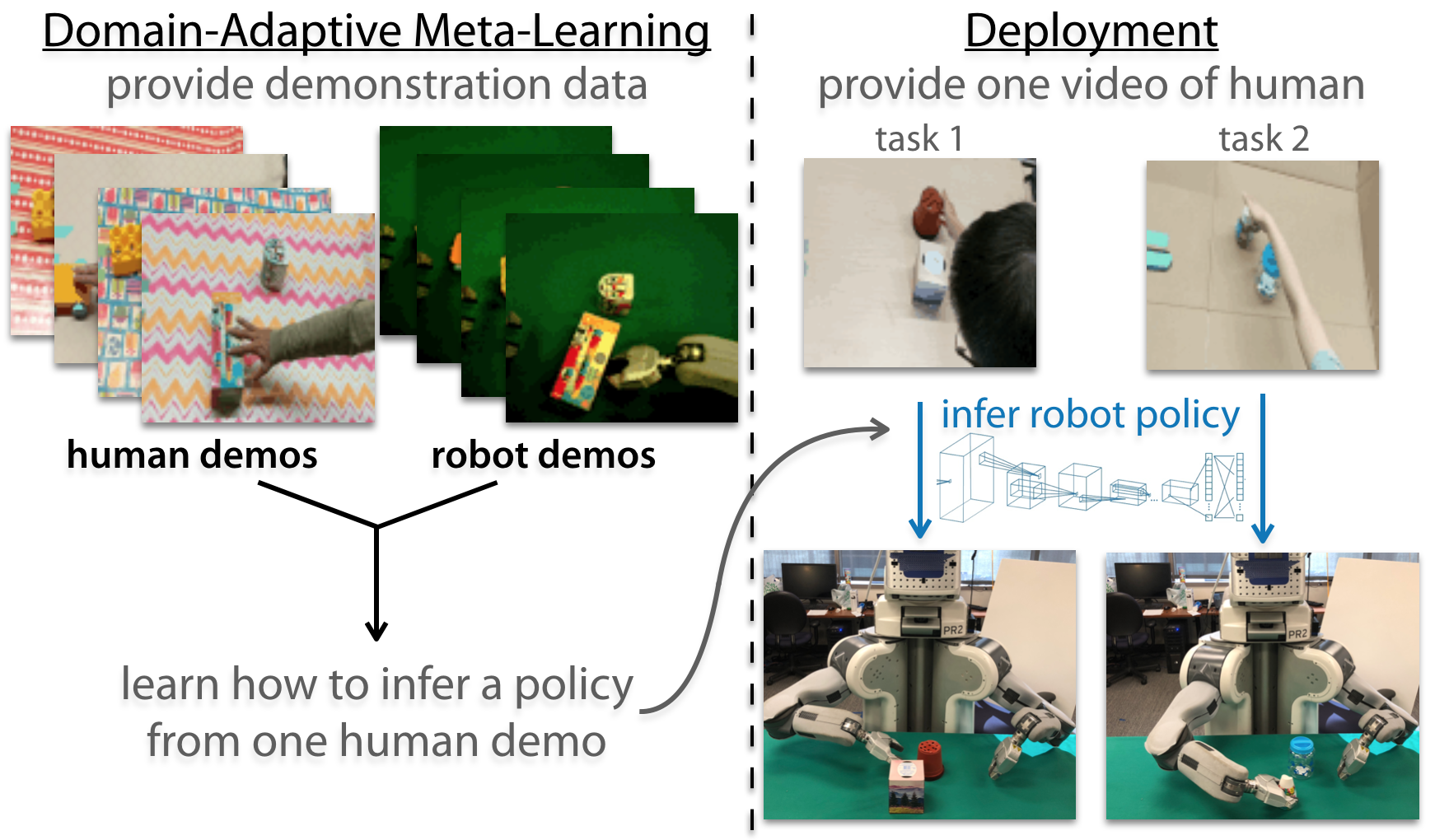
Overview of domain-adaptive meta-learning.
Unfortunately, as a human demonstration is just a video of a human performing the task, which doesn’t contain the expert actions , we can’t calculate the policy update defined above. Instead, we propose to learn a loss function for updating the policy, a loss function that doesn’t require action labels. The intuition behind learning a loss function is that we can acquire a function that only uses the available inputs, the unlabeled video, while still producing gradients that are suitable for updating the policy parameters in a way that produces a successful policy. While this might seem like an impossible task, it is important to remember that the meta-training process still supervises the policy with true robot actions after the gradient step. The role of the learned loss therefore may be interpreted as simply directing the parameter update to modify the policy to pick up on the right visual cues in the scene, so that the meta-trained action output will produce the right actions. We represent the learned loss function using temporal convolutions, which can extract temporal information in the video demonstration:
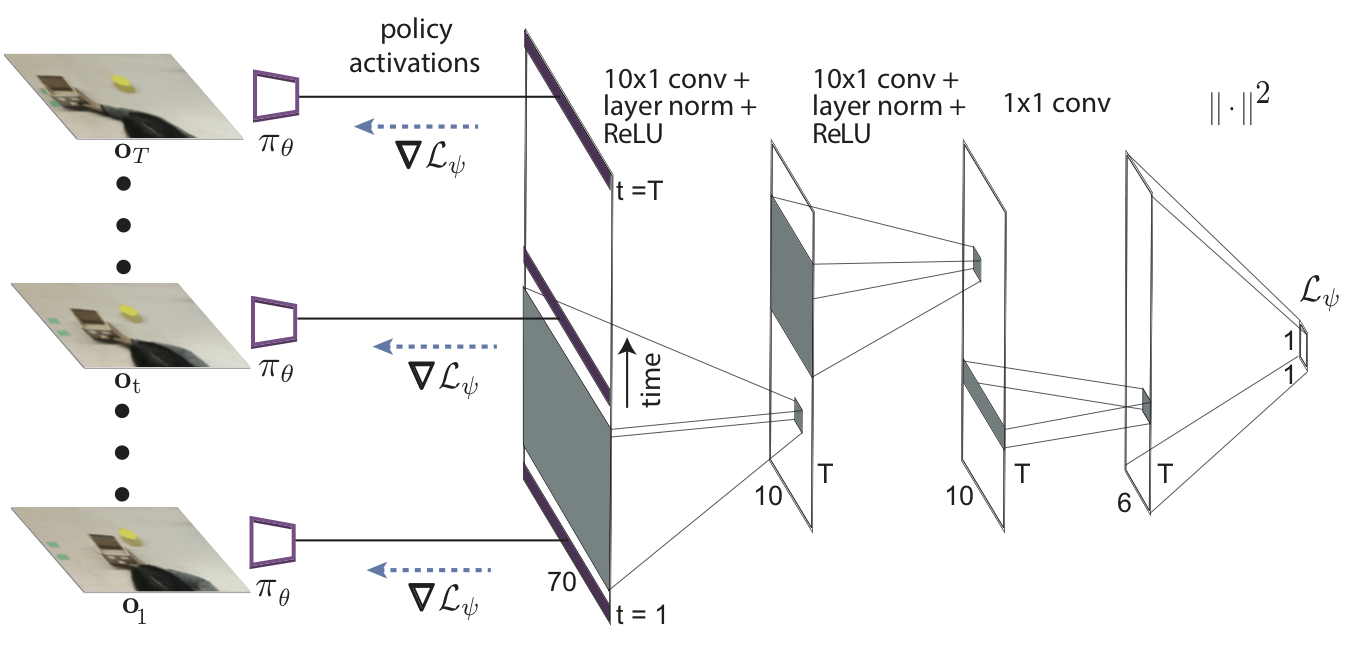
We refer to this method as domain-adaptive meta-learning algorithm, as it learns from data (e.g. videos of humans) from a different domain as the domain that the robot’s policy operates in. Our method enables a PR2 robot to effectively learn to push many different objects that are unseen during meta-training toward target positions:


Learning to push a novel object by watching a human.
and pick up many objects and place them onto target containers by watching a human manipulates each object:


Learning to pick up a novel object and place it into a previously unseen bowl.
We also evaluated the method using human demonstrations collected in a different room with a different camera. The robot still performs these tasks reasonably well:


Learning to push a novel object by watching a human in a different environment from a different viewpoint.
What’s Next?
Now that we’ve taught a robot to learn to manipulate new objects by watching a single video (which we also demonstrated at NIPS 2017), a natural next step is to further scale these approaches to the setting where different tasks correspond to entirely distinct motions and objectives, such as using a wide variety of tools or playing a wide variety of sports. By considering significantly more diversity in the underlying distribution of tasks, we hope that these models will be able to achieve broader generalization, allowing robots to quickly develop strategies for new situations. Further, the techniques we developed here are not specific to robotic manipulation or even control. For instance, both imitation learning and meta-learning have been used in the context of language (examples here and here respectively). In language and other sequential decision-making settings, learning to imitate from a few demonstrations is an interesting direction for future work.
We would like to thank Sergey Levine and Pieter Abbeel for valuable feedback when preparing this blog post. This article was initially published on the BAIR blog, and appears here with the authors’ permission.
This post is based on the following papers:
One-Shot Visual Imitation Learning via Meta-Learning
Finn C., Yu T., Zhang T., Abbeel P., Levine S. CoRL 2017
paper, code, videos
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
Yu T., Finn C., Xie A., Dasari S., Zhang T., Abbeel P., Levine S. RSS 2018
paper, video

AUAI is supported by:









