
Robohub.org
Simulations are the key to intelligent robots

I read an article entitled Games Hold the Key to Teaching Artificial Intelligent Systems, by Danny Vena, in which the author states that computer games like Minecraft, Civilization, and Grand Theft Auto have been used to train intelligent systems to perform better in visual learning, understand language, and collaborate with humans. The author concludes that games are going to be a key element in the field of artificial intelligence in the near future. And he is almost right.
In my opinion, the article only touches the surface of artificial intelligence by talking about games. Games have been a good starting point for the generation of intelligent systems that outperform humans, but going deeper into the realm of robots that are useful in human environments will require something more complex than games. And I’m talking about simulations.
Using games to bootstrap intelligence
The idea behind beating humans at games has been in artificial intelligence since its birth. Initially, researchers created programs to beat humans at Tic Tac Toe and Chess (like, for example, IBM’s DeepBlue). However, those games’ intelligence was programmed from scratch by human minds. There were people writing the code that decided which move should be the next one. However, that manual approach to generate intelligence reached a limit: intelligence is so complex that we realized that it may be too difficult to manually write a program that emulates it.
Then, a new idea was born: what if we create a system that learns by itself? In that case, the engineers will only have to program the learning structures and set the proper environment to allow intelligence to bootstrap by itself.

AlphaGo beats Lee Sedol
(photo credit: intheshortestrun)
The results of that idea are programs that learn to play the games better than anyone in the world, even if nobody explains to the program how to play in the first place. For example, Google’s DeepMind company created AlphaGo Zero program uses that approach. The program was able to beat the best players of Go in the world. The company used the same approach to create programs that learnt to play Atari games, starting from zero knowledge. Recently, OpenAI used this approach for their bot program that beats pro players of the Dota 2 game. By the way, if you want to reproduce the results of the Atari games, OpenAI released the OpenAI Gym, containing all the code to start training your system with Atari games, and compare the performance against other people.
What I took from those results is that the idea of making an intelligent system generate intelligence by itself is a good approach, and that the algorithms used for teaching can be used for making robots learn about their space (I’m not so optimistic about the way to encode the knowledge and to set the learning environment and stages, but that is another discussion).
From games to simulations
OpenAI wanted to go further. Instead of using games to generate programs that can play a game, they applied the same idea to make a robot do something useful: learn to manipulate a cube on its hand. In this case, instead of using a game, they used a simulation of the robot. The simulation was used to emulate the robot and its environment as if it were a real one. Then, they allowed the algorithm to control the simulated robot and make the robot learn about the task to solve by using domain randomization. After many trials, the simulated robot was able to manipulate the block in the expected way. But that was not all! At the end of the article, the authors successfully transferred the learned control program of the simulated robot to a real robot, which performed in a way similar to the simulated one. Except it was real.

Simulated Hand OpenAI Manipulation Experiment (image credit: OpenAI)

Real Hand OpenAI Manipulation Experiment (photo credit:OpenAI)
A similar approach was applied by OpenAI to a Fetch robot trained to grasp a spam box off of a table filled with different objects. The robot was trained in simulation and it was successfully transferred to the real robot.

OpenAI teaches Fetch robot to grasp from table using simulations (photo credit: OpenAI)
We are getting close to the holy grail in robotics, a complete self-learning system!
Training robots
However, in their experiments, engineers from OpenAI discovered that training for robots is a lot more complex than training algorithms for games. Meanwhile, in games, the intelligent system has a very limited list of actions and perceptions available; robots face a huge and continuous spectrum in both domains, actions and perceptions. We can say that the options are infinite.
That increase in the number of options diminishes the usefulness of the algorithms used for RL. Usually, the way to deal with the problem is with some artificial tricks, like discarding some of the information completely or discretizing the data values artificially, reducing the options to only a few.
OpenAI engineers found that even if the robots were trained in simulations, their approach could not scale to more complex tasks.
Massive data vs. complex learning algorithms
As Andrew Ng indicated, and as an engineer from OpenAI personally indicated to me based on his results, massive data with simple learning algorithms wins over complicated algorithms with a small amount of data. This means that it is not a good idea to try to focus on getting more complex learning algorithms. Instead, the best approach for reaching intelligent robotics would be to use simple learning algorithms trained with massive amounts of data (which makes sense if we observe our own brain: a massive amount of neural networks trained over many years).
Google has always known that. Hence, in order to obtain massive amounts of data to train their robots, Google created a real life system with real robots, training all day long in a large space. Even if it is a clever idea, we can all see that this is not practical in any sense for any kind of robot and application (breaking robots, limited to execution in real time, a limited amount of robots, a limited amount of environments, and so on…).

Google robots training for grasping
That leads us to the same solution again: to use simulations. By using simulations, we can put any robot in any situation and train them there. Also, we can have virtually an infinite number of them training in parallel, and generate massive amounts of data in record time.
Even if that approach looks very clear right now, it was not three years ago when we created our company, The Construct, around robot simulations in the cloud. I remember exhibiting at the Innorobo 2015 exhibition and finding, after extensive interviews among all the other exhibitors, that only two among them were using simulations for their work. Furthermore, roboticists considered simulations to be something nasty to be avoided at all cost, since nothing can compare with the real robot (check here for a post I wrote about it at the time).
Thankfully, the situation has changed since then. Now, using simulations for training real robots is starting to become the way.
Transferring to real robots
We all know that it is one thing to get a solution with the simulation and another for that solution to work on the real robot. Having something done by the robot in the simulation doesn’t imply that it will work the same way on the real robot. Why is that?
Well, there is something called the reality gap. We can define the reality gap as the difference between the simulation of a situation and the real-life situation. Since it is impossible for us to simulate something to a perfect degree, there will always be differences between simulation and reality. If the difference is big enough, it may happen that the results obtained in the simulator are not relevant at all. That is, you have a big reality gap, and what applies in the simulation does not apply to the real world.
That problem of the reality gap is one of the main arguments used to discard simulators for robotics. And in my opinion, the path to follow is not to discard the simulators and find something else, but instead to find solutions to cross that reality gap. As for solutions, I believe we have two options:
1. Create more accurate simulators. That is on its way. We can see efforts in this direction. Some simulators concentrate on better physics (Mujoco); others on a closer look at reality (Unreal or Unity-based simulators, like Carla or AirSim). We can expect that as computer power continues to increase, and cloud systems become more accessible, the accuracy of simulations is going to keep increasing in both senses, physics and looks.
2. Build better ways to cross the reality gap. In its original work, Noise and the reality gap, Jakobi (the person who identified the problem of the reality gap) indicated that one of the first solutions is to make a simulation independent of the reality gap. His idea was to introduce noise in those variables that are not relevant to the task. The modern version of that noise introduction is the concept of domain randomization, as described in the paper Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World.
Domain randomization basically consists of performing the training of the robot in a simulated environment where its non-relevant-to-the-task features are changed randomly, like the colors of the elements, the light conditions, the relative position to other elements, etc.
The goal is to make the trained algorithm be unaffected by those elements in the scene that provide no information to the task at hand, but which may confuse it (because the algorithm doesn’t know which parts are the relevant ones to the task). I can see domain randomization as a way to tell the algorithm where to focus its attention, in terms of the huge flow of data that it is receiving.

Domain randomization applied by OpenAI to train a Fetch robot in simulation (photo credit: OpenAI)
In more recent works, the OpenAI team has released a very interesting paper that improves domain randomization. They introduce the concept of dynamics randomization. In this case, it is not the environment that is changing in the simulation, but the properties of the robot (like its mass, distance between grippers, etc.). The paper is Sim-to-real transfer of robotic control with dynamics randomization. That is the approach that OpenAI engineers took to successfully achieve the manipulation robot.
Some software that goes on the line
What follows is a list of software that allows the training of robots in simulations. I’m not including just robotics simulators (like Gazebo, Webots, and V-Rep) because they are just that, robot simulators in the general sense. The software listed here goes one step beyond that and provides a more complete solutions for doing the training in simulations. Of course, I have discarded the system used by OpenAI (which is Mujoco) because it requires the building of your own development environment.
Carla
Carla is an open source simulator for self-driving cars based on Unreal Engine. It has recently included a ROS bridge.

Carla simulator (photo credit Carla)
Microsoft Airsim
Microsoft Airsim drones simulator follows a similar approach to Carla, but for drones. Recently, they updated the simulator to also include self-driving cars.

Airsim (photo credit: Microsoft)
Nvidia Isaac
Nvidia Isaac aims to be a complete solution for training robots on simulations and then transferring to real robots. There is still nothing available, but they are working on it.

Isaac (photo credit: Nvidia)
ROS Development Studio
The ROS Development Studio is the development environment that our company created, and it has been conceived from the beginning to simulate and train any ROS-based robot, requiring nothing to be installed in your computer (cloud-based). Simulations for the robots are already provided with all the ROS controllers up and running, as well as the machine learning tools. It includes a system of Gym cloud computers for the parallel training of robots on an infinite number of computers.
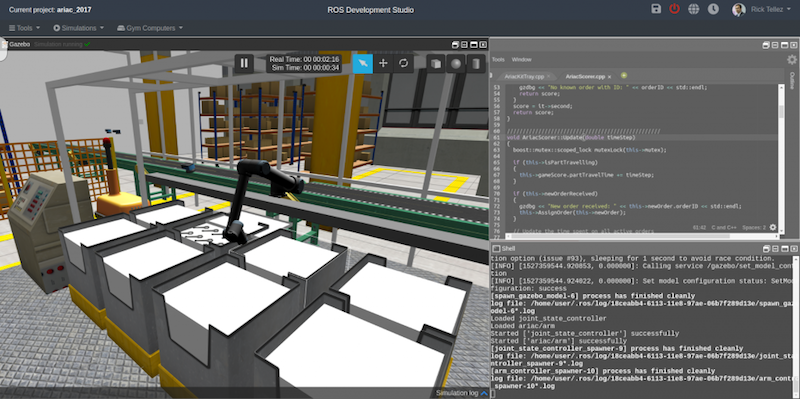
ROS Development Studio showing an industrial environment
Here is a video showing a simple example of training two cartpoles in parallel using the Gym computers inside the ROS Development Studio:
(Readers, if you know other software like this that I can add, let me know.)
Conclusion
Making all those deep neural networks learn in a training simulation is the way to go, and as we may see in the future, this is just the tip of the iceberg. My personal opinion is that intelligence is yet more embodied than current AI approaches admit: you cannot have intelligence without a body. Hence, I believe that the use of simulated embodiments will be even higher in the future. We’ll see.

AUAI is supported by:









