
Robohub.org
Interview with Tao Chen, Jie Xu and Pulkit Agrawal: CoRL 2021 best paper award winners
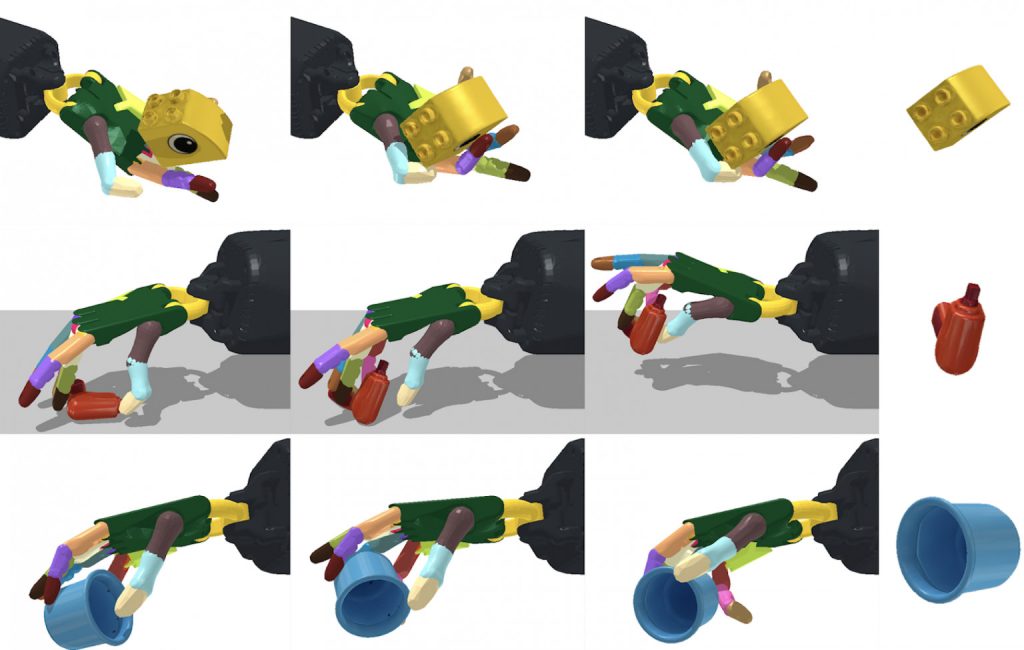
Congratulations to Tao Chen, Jie Xu and Pulkit Agrawal who have won the CoRL 2021 best paper award!
Their work, A system for general in-hand object re-orientation, was highly praised by the judging committee who commented that “the sheer scope and variation across objects tested with this method, and the range of different policy architectures and approaches tested makes this paper extremely thorough in its analysis of this reorientation task”.
Below, the authors tell us more about their work, the methodology, and what they are planning next.
What is the topic of the research in your paper?
We present a system for reorienting novel objects using an anthropomorphic robotic hand with any configuration, with the hand facing both upwards and downwards. We demonstrate the capability of reorienting over 2000 geometrically different objects in both cases. The learned controller can also reorient novel unseen objects.
Could you tell us about the implications of your research and why it is an interesting area for study?
Our learned skill (in-hand object reorientation) can enable fast pick-and-place of objects in desired orientations and locations. For example, in logistics and manufacturing, it is a common demand to pack objects into slots for kitting. Currently, this is usually achieved via a two-stage process involving re-grasping. Our system will be able to achieve it in one step, which can substantially improve the packing speed and boost the manufacturing efficiency.
Another application is enabling robots to operate a wider variety of tools. The most common end-effector in industrial robots is a parallel-jaw gripper, partially due to its simplicity in control. However, such an end-effector is physically unable to handle many tools we see in our daily life. For example, even using pliers is difficult for such a gripper as it cannot dexterously move one handle back and forth. Our system will allow a multi-fingered hand to dexterously manipulate such tools, which opens up a new area for robotics applications.
Could you explain your methodology?
We use a model-free reinforcement learning algorithm to train the controller for reorienting objects. In-hand object reorientation is a challenging contact-rich task. It requires a tremendous amount of training. To speed up the learning process, we first train the policy with privileged state information such as object velocities. Using the privileged state information drastically improves the learning speed. Other than this, we also found that providing a good initialization on the hand and object pose is critical for training the controller to reorient objects when the hand faces downward. In addition, we develop a technique to facilitate the training by building a curriculum on gravitational acceleration. We call this technique “gravity curriculum”.
With these techniques, we are able to train a controller that can reorient many objects even with a downward-facing hand. However, a practical concern of the learned controller is that it makes use of privileged state information, which can be nontrivial to get in the real world. For example, it is hard to measure the object’s velocity in the real world. To ensure that we can deploy a controller reliably in the real world, we use teacher-student training. We use the controller trained with the privileged state information as the teacher. Then we train a second controller (student) that does not rely on any privileged state information and hence has the potential to be deployed reliably in the real world. This student controller is trained to imitate the teacher controller using imitation learning. The training of the student controller becomes a supervised learning problem and is therefore sample-efficient. In the deployment time, we only need the student controller.
What were your main findings?
We developed a general system that can be used to train controllers that can reorient objects with either the robotic hand facing upward or downward. The same system can also be used to train controllers that use external support such as a supporting surface for object re-orientation. Such controllers learned in our system are robust and can also reorient unseen novel objects. We also identified several techniques that are important for training a controller to reorient objects with a downward-facing hand.
A priori one might believe that it is important for the robot to know about object shape in order to manipulate new shapes. Surprisingly, we find that the robot can manipulate new objects without knowing their shape. It suggests that robust control strategies mitigate the need for complex perceptual processing. In other words, we might need much simpler perceptual processing strategies than previously thought for complex manipulation tasks.
What further work are you planning in this area?
Our immediate next step is to achieve such manipulation skills on a real robotic hand. To achieve this, we will need to tackle many challenges. We will investigate overcoming the sim-to-real gap such that the simulation results can be transferred to the real world. We also plan to design new robotic hand hardware through collaboration such that the entire robotic system can be dexterous and low-cost.
About the authors
 Tao Chen is a Ph.D. student in the Improbable AI Lab at MIT CSAIL, advised by Professor Pulkit Agrawal. His research interests revolve around the intersection of robot learning, manipulation, locomotion, and navigation. More recently, he has been focusing on dexterous manipulation. His research papers have been published in top AI and robotics conferences. He received his master’s degree, advised by Professor Abhinav Gupta, from the Robotics Institute at CMU, and his bachelor’s degree from Shanghai Jiao Tong University.
Tao Chen is a Ph.D. student in the Improbable AI Lab at MIT CSAIL, advised by Professor Pulkit Agrawal. His research interests revolve around the intersection of robot learning, manipulation, locomotion, and navigation. More recently, he has been focusing on dexterous manipulation. His research papers have been published in top AI and robotics conferences. He received his master’s degree, advised by Professor Abhinav Gupta, from the Robotics Institute at CMU, and his bachelor’s degree from Shanghai Jiao Tong University.
 Jie Xu is a Ph.D. student at MIT CSAIL, advised by Professor Wojciech Matusik in the Computational Design and Fabrication Group (CDFG). He obtained a bachelor’s degree from Department of Computer Science and Technology at Tsinghua University with honours in 2016. During his undergraduate period, he worked with Professor Shi-Min Hu in the Tsinghua Graphics & Geometric Computing Group. His research mainly focuses on the intersection of Robotics, Simulation, and Machine Learning. Specifically, he is interested in the following topics: robotics control, reinforcement learning, differentiable physics-based simulation, robotics control and design co-optimization, and sim-to-real.
Jie Xu is a Ph.D. student at MIT CSAIL, advised by Professor Wojciech Matusik in the Computational Design and Fabrication Group (CDFG). He obtained a bachelor’s degree from Department of Computer Science and Technology at Tsinghua University with honours in 2016. During his undergraduate period, he worked with Professor Shi-Min Hu in the Tsinghua Graphics & Geometric Computing Group. His research mainly focuses on the intersection of Robotics, Simulation, and Machine Learning. Specifically, he is interested in the following topics: robotics control, reinforcement learning, differentiable physics-based simulation, robotics control and design co-optimization, and sim-to-real.
 Dr Pulkit Agrawal is the Steven and Renee Finn Chair Professor in the Department of Electrical Engineering and Computer Science at MIT. He earned his Ph.D. from UC Berkeley and co-founded SafelyYou Inc. His research interests span robotics, deep learning, computer vision and reinforcement learning. Pulkit completed his bachelor’s at IIT Kanpur and was awarded the Director’s Gold Medal. He is a recipient of the Sony Faculty Research Award, Salesforce Research Award, Amazon Machine Learning Research Award, Signatures Fellow Award, Fulbright Science and Technology Award, Goldman Sachs Global Leadership Award, OPJEMS, and Sridhar Memorial Prize, among others.
Dr Pulkit Agrawal is the Steven and Renee Finn Chair Professor in the Department of Electrical Engineering and Computer Science at MIT. He earned his Ph.D. from UC Berkeley and co-founded SafelyYou Inc. His research interests span robotics, deep learning, computer vision and reinforcement learning. Pulkit completed his bachelor’s at IIT Kanpur and was awarded the Director’s Gold Medal. He is a recipient of the Sony Faculty Research Award, Salesforce Research Award, Amazon Machine Learning Research Award, Signatures Fellow Award, Fulbright Science and Technology Award, Goldman Sachs Global Leadership Award, OPJEMS, and Sridhar Memorial Prize, among others.
Find out more
- Read the paper on arXiv.
- The videos of the learned policies are available here, as is a video of the authors’ presentation at CoRL.
- Read more about the winning and shortlisted papers for the CoRL awards here.
tags: Algorithm AI-Cognition, c-Research-Innovation

AUAI is supported by:









