
Robohub.org
Planning robot motions that humans can relate to
This post is part of our ongoing efforts to make the latest papers in robotics accessible to a general audience.
Imagine a scenario where a robot and a human are collaborating side by side to perform a tightly coupled physical task together, like clearing a table.
The task amplifies the burden on the robot’s motion. Most motion in robotics is purely functional: industrial robots move to package parts, vacuuming robots move to suck dust, and personal robots move to clean up a dirty table. This type of motion is ideal when the robot is performing a task in isolation.
Collaboration, however, does not happen in isolation. In collaboration, the robot’s motion has a human observer, watching and interpreting the motion.
In a recent paper in Autonomous Robots, Dragan et al. move beyond functional motion, and introduce the notion of an observer and their inferences into motion planning, so that robots can generate motion that is mindful of how it will be interpreted by a human collaborator.
When we collaborate, we make two inferences about our collaborator, action-to-goal and goal-to-action, leading to two important motion properties: legibility and predictability.
Legibility is about conveying intent — moving in a manner that makes the robot’s goal clear to the observer; we infer the robot’s goal based on its ongoing action (action-to-goal). Predictability is about matching the observer’s expectation — matching the motion they predict when they know the robot’s goal; if we know the robot’s goal, we infer its future action from it (goal-to-action).
Predictable and legible motion can be correlated. For example, in an unambiguous situation, where an actor’s observed motion matches what is expected for a given intent (i.e. is predictable), then this intent can be used to explain the motion. If this is the only intent which explains the motion, the observer can immediately infer the actor’s intent, meaning that the motion is also legible. This is why we tend to assume that predictability implies legibility — that if the robot moves in an expected way, then its intentions will automatically be clear. But this isn’t necessarily the case.
The context of handwriting can help us understand what distinguishes these two concepts. Traditionally an attribute of handwritten text, the word “legibility” refers to the quality of being “easy to read”. When we write legibly, we try consciously, and with some effort, to make our writing clear and readable to someone else, the way we would if we were writing an essay for a teacher or a letter for a friend. The word “predictability”, on the other hand, refers to the quality of matching expectation. When we write predictably, we fall back to old habits, and write with minimal effort, the way we might if we were taking lecture notes or writing in a personal diary.
Our legible handwriting is meant to be observed and understood, while our predictable handwriting need only be understood by ourselves. As a consequence, our “legible” and “predictable” handwriting look different. Our friends do not expect to open our personal diary and see our legible writing style … they rightfully assume the diary is meant for personal use, and would expect to see our day-to-day (and perhaps hard to understand) handwriting; our friends might be frustrated, however, if we used this same handwriting to write them a letter.
By formalizing predictability and legibility as directly stemming from the two inferences in opposing directions, goal-to-action and action-to-goal, we show that the two are different in motion as well.
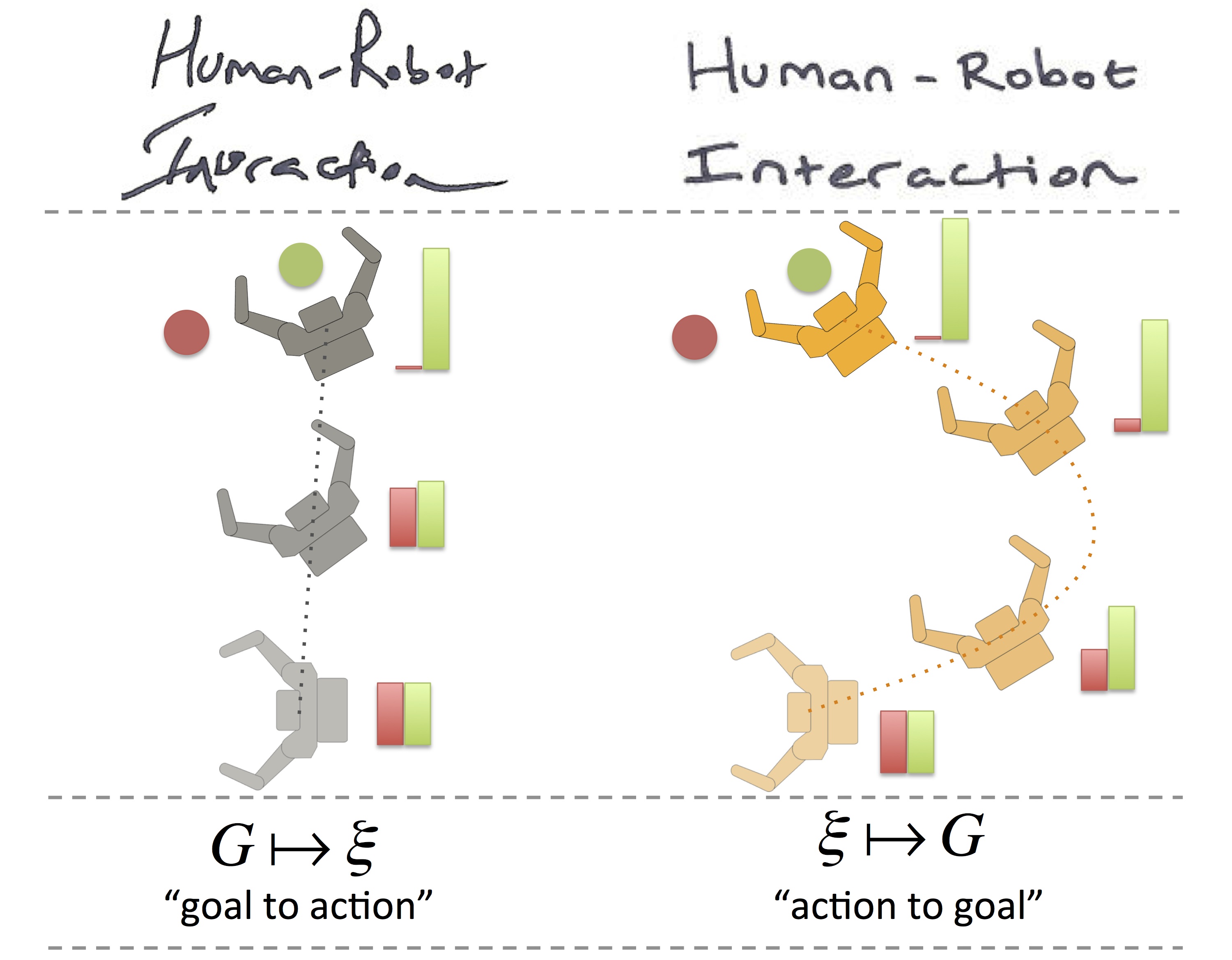
Ambiguous situations (occurring often in daily tasks) make this opposition clear: more than one possible intent can be used to explain the motion observed so far, rendering the predictable motion illegible. The figure above exemplifies the effect of this contradiction. The robot hand’s motion on the left is predictable in that it matches expected behavior. The hand reaches out directly towards the target. And yet it is not legible, as it fails to make the intent of grasping the green object clear. In contrast, the trajectory on the right is more legible, making it clear that the target is the green object by deliberately bending away from the red object. But it is less predictable, as it does not match the expected behavior of reaching directly.
Dragan et al. produce predictable and legible motion by mathematically modeling how humans infer motion from goals and goals from motion, and introducing trajectory optimizers that maximize the probability that the right inferences will be made. The figure below shows the robot starting with a predictable trajectory (gray) and optimizing it to be more and more legible (orange).
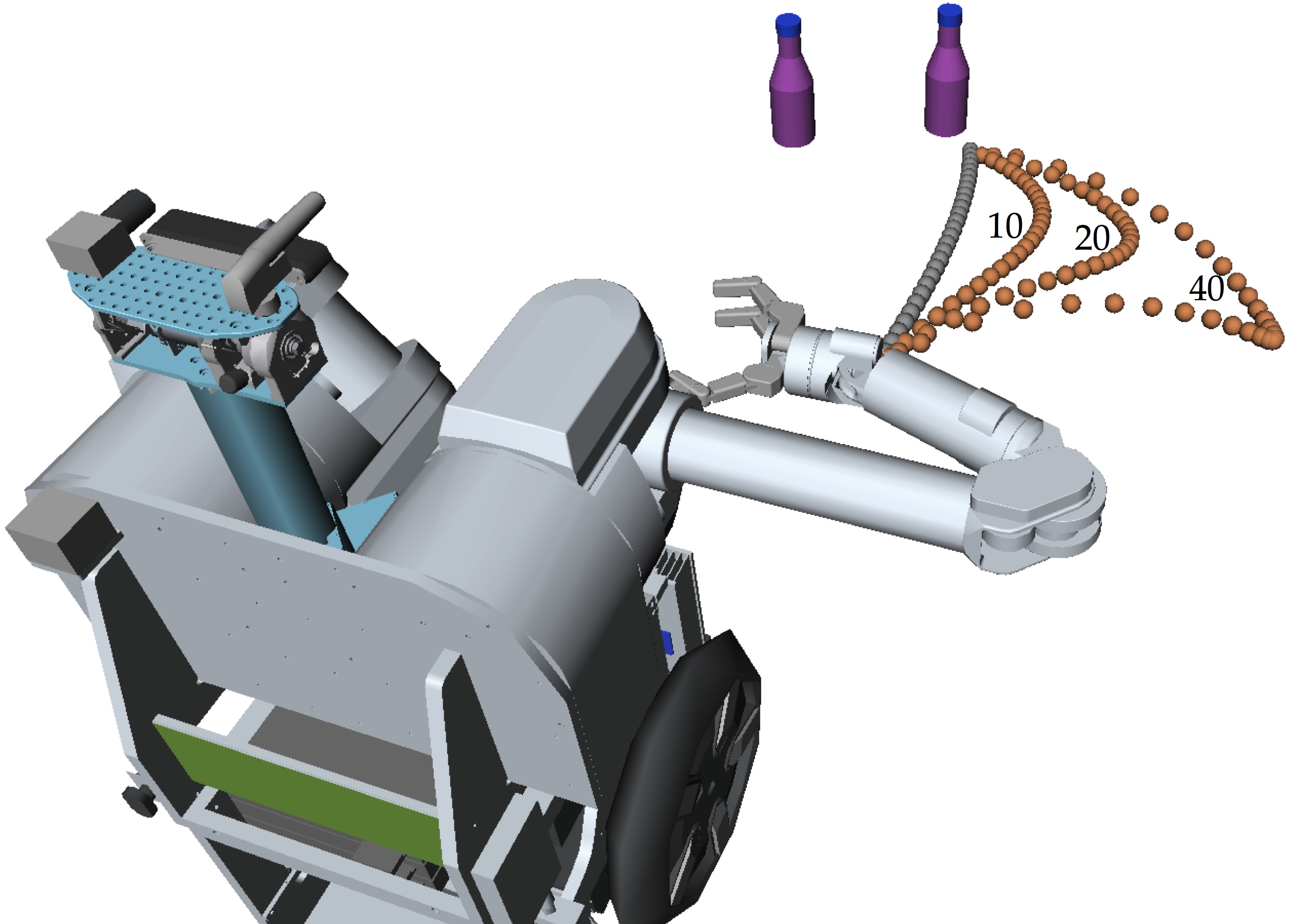
By exaggerating the motion to the right, it becomes more immediately clear that the robot’s goal is the object on the right. Exaggeration is one of the principles of Disney animation, and it naturally emerges out of the mathematics of legible motion.
For more information, you can read the paper Integrating human observer inferences into robot motion plannings (Anca Dragan, Siddhartha Srinivasa, Autonomous Robots – Springer US, August 2014) or ask questions below!
tags: c-Research-Innovation, human-robot interaction

AUAI is supported by:









