
Robohub.org
SXSW 2018: Protect AI, robots, cars (and us) from bias

As Mark Hamill humorously shared the behind-the-scenes of “Star Wars: The Last Jedi” with a packed SXSW audience, two floors below on the exhibit floor Universal Robots recreated General Grievous’ famed light saber battles. The battling machines were steps away from a twelve foot dancing Kuka robot and an automated coffee dispensary. Somehow the famed interactive festival known for its late night drinking, dancing and concerts had a very mechanical feel this year. Everywhere debates ensued between utopian tech visionaries and dystopia-fearing humanists.
Even my panel on “Investing In The Autonomy Economy” took a very social turn when discussing the opportunities of utilizing robots for the growing aging population. Eric Daimler (formerly of the Obama White House) raised concerns about AI bias affecting the well being of seniors. Agreeing, Dan Burstein (partner at Millennium Tech Value Partners) nervously expressed that ‘AI is everywhere, in everything, and the USA has no other way to care for this exploding demographic except with machines.’ Daimler explained that “AI is very good at perception, just not context;” until this is solved it could be a very dangerous problem worldwide.
Last year at a Google conference on the relationship between humans and AI, the company’s senior vice president of engineering, John Giannandrea, warned, “The real safety question, if you want to call it that, is that if we give these systems biased data, they will be biased. It’s important that we be transparent about the training data that we are using, and are looking for hidden biases in it, otherwise we are building biased systems.” Similar to Daimler’s anxiety about AI and healthcare, Giannandrea exclaimed that “If someone is trying to sell you a black box system for medical decision support, and you don’t know how it works or what data was used to train it, then I wouldn’t trust it.”

One of the most famous illustrations of how quickly human bias influences computer actions is Tay, the Microsoft customer service chatbot on Twitter. It took only twenty-four hours for Tay to develop a Nazi persona leading to more than ninety thousand hate-filled tweets. Tay swiftly calculated that hate on social media equals popularity. In explaining its failed experiment to Business Insider Microsoft stated via email: “The AI chatbot Tay is a machine learning project, designed for human engagement. As it learns, some of its responses are inappropriate and indicative of the types of interactions some people are having with it. We’re making some adjustments to Tay.”
While Tay’s real impact was benign, it raises serious questions of the implications of embedding AI into machines and society. In its Pulitzer Prize-winning article, ProPublica.org uncovered that a widely distributed US criminal justice software called Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) was racially biased in scoring the risk levels of convicted felons to recommit crimes. ProPublica discovered that black defendants in Florida, “were far more likely than white defendants to be incorrectly judged to be at a higher rate of recidivism” by the AI. Northpointe, the company that created COMPAS, released its own report that disputed ProPublica’s findings but it refused to pull back the curtain on its training data, keeping the algorithms hidden in a “black box.” In a statement released to the New York Times, Northpointe’s spokesperson argued, “The key to our product is the algorithms, and they’re proprietary. We’ve created them, and we don’t release them because it’s certainly a core piece of our business.”

The dispute between Northpointe and ProPublica raises the question of transparency and the auditing of data by an independent arbitrator to protect against bias. Cathy O’Neil, a former Barnard professor and analyst at D.E. Shaw, thinks a lot about safeguarding ordinary Americans from biased AI. In her book, Weapons of Math Destruction, she cautions that big corporate America is too willing to hand over the wheel to the algorithms without fully assessing the risks or implementing any oversight monitoring. “[Algorithms] replace human processes, but they’re not held to the same standards. People trust them too much,” declares O’Neil. Understanding the high stakes and lack of regulatory oversight by the current federal government, O’Neil left her high-paying Wall Street job to start a software auditing firm, O’Neil Risk Consulting & Algorithmic Auditing. In an interview with MIT Technology Review last summer, O’Neil frustratingly expressed that companies are more interested in the bottom line than protecting their employees, customers, and families from bias, “I’ll be honest with you. I have no clients right now.”

Most of the success of deconstructing “black boxes” is happening today at the US Department of Defense. DARPA has been funding the research of Dr. David Gunning to develop Explainable Artificial Intelligence (XAI). Understanding its own AI and that of foreign governments could be a huge advantage for America’s cyber military units. At the same time, like many DARPA-funded projects, civilian opportunities could offer societal benefits. According to Gunning’s statement, online XAI aims to “produce more explainable models, while maintaining a high level of learning performance (prediction accuracy); and enable human users to understand, appropriately trust, and effectively manage the emerging generation of artificially intelligent partners.” XAI plans to work with developers and user interfaces designers to foster “useful explanation dialogues for the end user,” to know when to trust or question the AI-generated data.
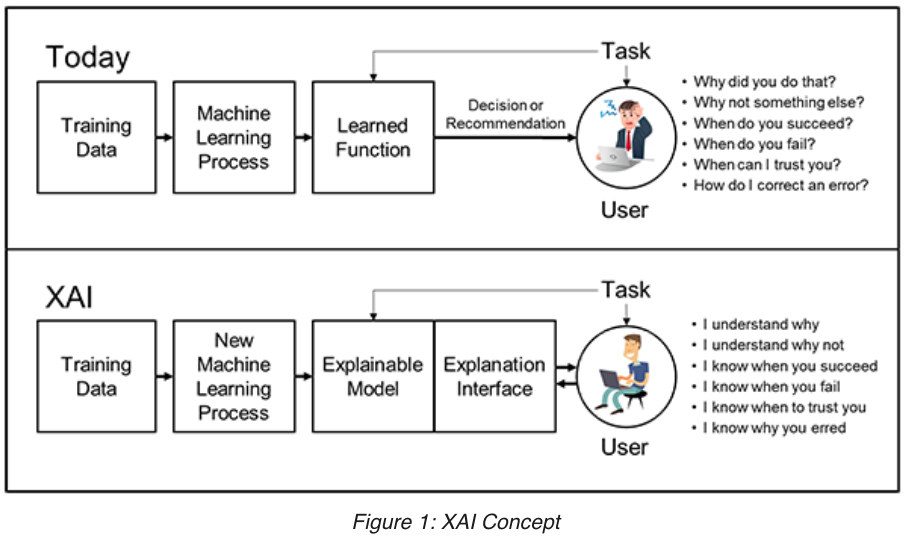
Besides DARPA, many large technology companies and universities are starting to create think tanks, conferences and policy groups to develop standards that test AI bias. The results have been startling – ranging from computer vision sensors that negatively identify people of color to gender bias in employment management software to blatant racism of natural language processing systems to security robots that run over kids identified mistakenly as threats. As an example of how training data affects outcomes, when Google first released its image processing software, the AI identified photos of African Americans as “gorillas,” because the engineers failed to provide enough minority examples into the neural network.
Ultimately artificial intelligence reflects the people that program it, as every human being brings with him his own experiences that shape personal biases. According to Kathleen Walch, host of AI Today podcast, “If the researchers and developers developing our AI systems are themselves lacking diversity, then the problems that AI systems solve and training data used both become biased based on what these data scientists feed into AI training data,” Walch advocates that hiring diversity can bring “about different ways of thinking, different ethics and different mindsets. Together, this creates more diverse and less biased AI systems. This will result in more representative data models, diverse and different problems for AI solutions to solve, and different use cases feed to these systems if there is a more diverse group feeding that information.”

Before leaving SXSW, I attended a panel hosted by the IEEE on “Algorithms, Unconscious Bias & AI,” amazingly all led by female panelists including one person of color. Hiring basis became a big theme of their discussion. Following the talk, I hopped into my Uber and pleasantly rode to the airport reflecting on a statement made earlier in the day by John Krafcik, Cheif Executive, of Waymo. Krafcik boasted that Waymo’s mission is to build “the world’s most experienced driver,” I just hope that the training data is not from New York City cabbies.



