
Robohub.org
Experiments designing an ethical robot
In my last post I wrote about our work on robots with internal models: robots with a simulation of themselves and their environment inside themselves. I explained that we have built a robot with a real-time Consequence Engine, which allows it to model and therefore predict the consequences of both its own actions, and the actions of other actors in its environment.
To test the robot and its consequence engine we ran two sets of experiments. Our first paper, setting out the results from one of those experiments, has now been published, and was presented at the conference Towards Autonomous Robotics (TAROS). The paper is called: Towards an Ethical Robot: Internal Models, Consequences and Ethical Action Selection. Let me now outline the work in that paper.
First, here is a simple thought experiment. Imagine a robot that’s heading toward a hole in the ground. The robot can sense the hole, and has four possible next actions: stand still, turn toward the left, continue straight ahead, or move toward the right. But imagine there’s also a human heading toward the hole, and the robot can also sense the human.
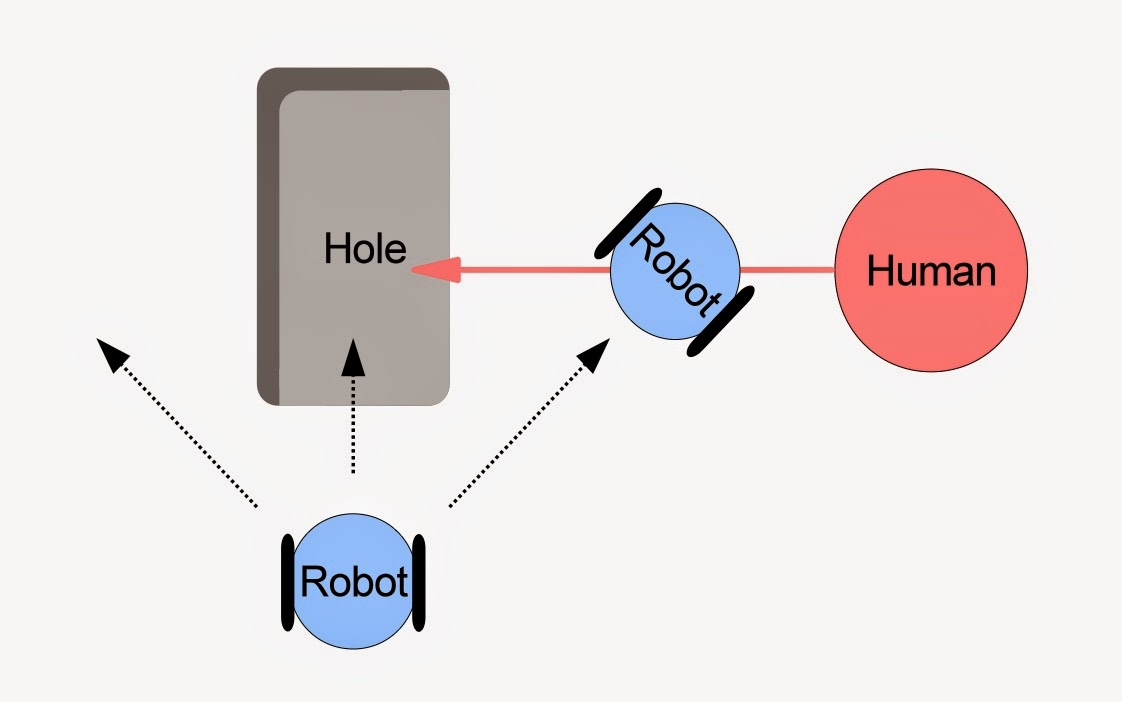
From the robot’s perspective, it has two safe options: stand still, or turn to the left. Go straight ahead and it will fall into the hole. Turn right and it is likely to collide with the human.
But if the robot, with its consequence engine, can model the consequences of both its own actions and the human’s – another possibility opens up: the robot could sometimes choose to collide with the human to prevent her from falling into the hole.
Here’s a simple rule for this behaviour:
IF for all robot actions, the human is equally safe
THEN (* default safe actions *)
output safe actions
ELSE (* ethical action *)
output action(s) for least unsafe human outcome(s)
This rule appears to match remarkably well with Asimov’s first law of robotics: A robot may not injure a human being or, through inaction, allow a human being to come to harm. The robot will avoid injuring (i.e. colliding with) a human (may not injure a human), but may also sometimes compromise that rule in order to prevent a human from coming to harm (… or, through inaction, allow a human to come to harm). And Asimov’s third law: A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
Well, we tested this scenario with real robots: one robot with consequence engine plus ethical rule (the A-robot – after Asimov), and another robot acting as a proxy human (the H-robot). And it works!
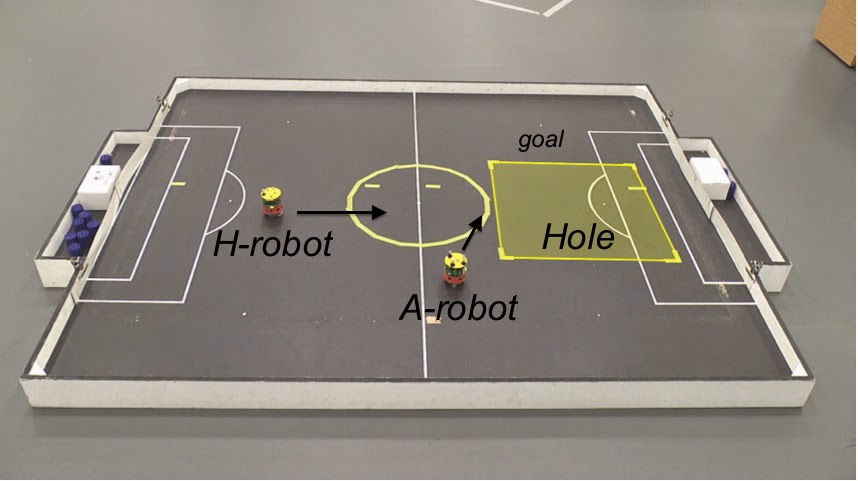
Here’s what the real robot experiment looks like. We don’t have a real hole. Instead a virtual hole – the yellow shaded square on the right. We just ‘tell’ the A-robot where the hole is. We also give the A-robot a goal position – at the top right – chosen so that the robot must actively avoid the hole. The H-robot on the right, acting as a proxy human, doesn’t ‘see’ the hole and just heads straight for it. (Ignore the football pitch markings – we’re re-using this handy robo-soccer pitch.)
So, what happens? For comparison we ran two trials, with multiple runs in each trial. In the first trial is just the A-robot, moving toward its goal while avoiding falling into the hole. In the second trial we introduce the H-robot. The graphs below show the robot trajectories, captured by our robot tracking system, for each run in each of the two trials.
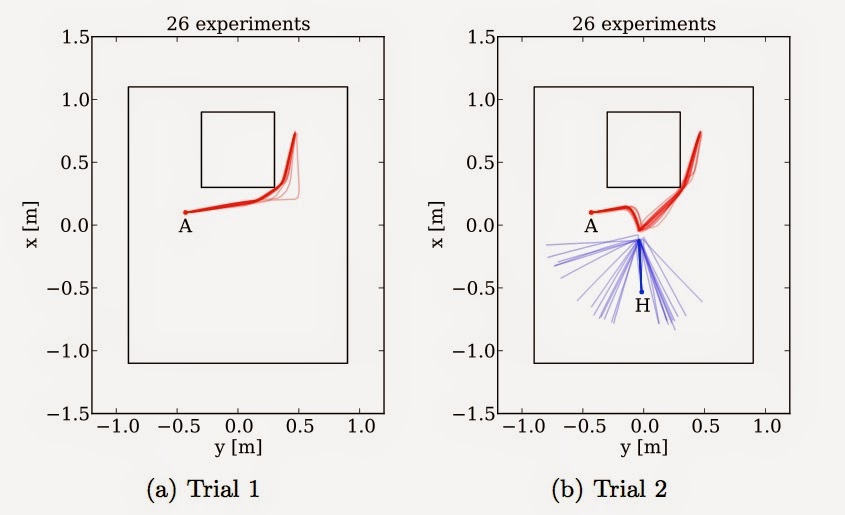
In trial 1, see how the A-robot neatly clips the corner of the hole to reach its goal position. Then in trial 2, see how the A robot initially moves toward it’s goal, then notices that the H-robot is in danger of falling into the hole, so it diverts from its trajectory in order to head-off H. By provoking a collision avoidance behaviour by H, A sends it off safely away from the hole, before then resuming its own progress toward its goal position. The A-robot is 100% successful in preventing H from falling into the hole.
At this point we started to write the paper, but felt we needed something more than “we built it and it works just fine”. So we introduced a third robot – acting as a second proxy human. So now our ethical robot would face a dilemma – which one should it rescue? Actually we thought hard about this question and decided not to programme a rule, or heuristic. Partly because such a rule should be decided by ethicists, not engineers, and partly because we wanted to test our ethical robot with a ‘balanced’ dilemma.
We set the experiment up carefully so that the A-robot would notice both H-robots at about the same time – noting that because these are real physical robots then no two experimental runs will be exactly identical. The results were very interesting. Out of 33 runs, 16 times the A-robot managed to rescue one of the H-robots, but not the other, and amazingly, 3 times the A-robot rescued both. In those 3 cases, by chance the A-robot rescued the first H-robot very quickly and there was just enough time to get to the second before it reached the hole. Small differences in the trajectories of H and H2 helped here. But perhaps most interesting were the 14 times when the A-robot failed to rescue either. Why is this, when there is clearly time to rescue one? When we studied the videos, we see the answer. The problem is that the A-robot sometimes dithers. It notices one H-robot, starts toward it but then almost immediately notices the other. It changes its mind. And the time lost dithering means the A-robot cannot prevent either robot from falling into the hole. Here are the results.
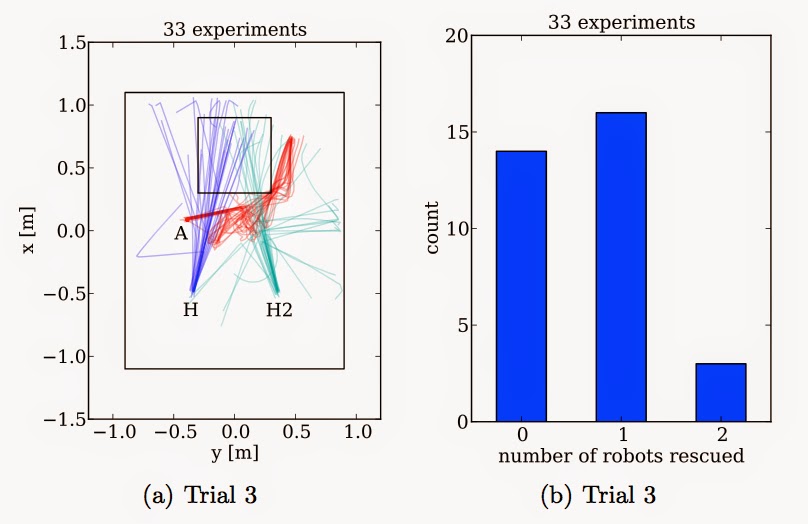
Here is an example of a typical run, in which one H-robot is rescued. But note that the A-robot does then turn briefly toward the other H-robot before ‘giving-up’.
And here is a run in which the A-robot fails to rescue either H-robot, with really great dithering (or bad, if you’re an H-robot).
Is this the first experimental test of a robot facing an ethical dilemma?
So, we set out to experimentally test our robot with a consequence engine, and we ended up building a minimally ethical robot that – remarkably – appears to implement Asimov’s 1st and 3rd laws of robotics . But, as we say in the paper, we’re not claiming that a robot which apparently implements part of Asimov’s famous laws is ethical in any formal sense, i.e. that an ethicist might accept. But even minimally ethical robots could be useful. I think our approach is a step in this direction.
Full paper reference:
Winfield AFT, Blum C and Liu W (2014), Towards an Ethical Robot: Internal Models, Consequences and Ethical Action Selection, pp 85-96 in Advances in Autonomous Robotics Systems, Lecture Notes in Computer Science Volume 8717, Eds. Mistry M, Leonardis A, Witkowski M and Melhuish C, Springer, 2014.
Acknowledgements:
I am hugely grateful to Christian Blum who programmed the robots, set up the experiment and obtained the results outlined here. Christian was supported by Dr Wenguo Liu.
Related blog posts:
On internal models, consequence engines and Popperian creatures
Ethical Robots: some technical and ethical challenges
tags: Alan Winfield, c-Research-Innovation, EU perspectives, roboethics



