
Robohub.org
Noisy imitation speeds up group learning
Broadly speaking there are two kinds of learning: individual learning and social learning. Individual learning means learning something entirely on your own, without reference to anyone else who might have learned the same thing before. The flip side of individual learning is social learning, which means learning from someone else. We humans are pretty good at both individual and social learning although we very rarely have to truly work something out from first principles.  Most of what we learn, we learn from teachers, parents, grandparents and countless others. We learn everything from how to make chicken soup to flying an aeroplane from watching others who already know the recipe (or wrote it down), or have mastered the skill. For modern humans I reckon it’s pretty hard to think of anything we have truly learned, on our own; maybe learning to control our own bodies as babies, leading to crawling and walking are candidates for individual learning (although as babies we are surrounded by others who already know how to walk – would we walk at all if everyone else got around on all fours?). Learning to ride a bicycle is perhaps also one of those things no-one can really teach you – although it would be interesting to compare someone who has never seen a bicycle, or anyone riding one, in their lives with those (most of us) who see others riding bicycles long before climbing on one ourselves.
Most of what we learn, we learn from teachers, parents, grandparents and countless others. We learn everything from how to make chicken soup to flying an aeroplane from watching others who already know the recipe (or wrote it down), or have mastered the skill. For modern humans I reckon it’s pretty hard to think of anything we have truly learned, on our own; maybe learning to control our own bodies as babies, leading to crawling and walking are candidates for individual learning (although as babies we are surrounded by others who already know how to walk – would we walk at all if everyone else got around on all fours?). Learning to ride a bicycle is perhaps also one of those things no-one can really teach you – although it would be interesting to compare someone who has never seen a bicycle, or anyone riding one, in their lives with those (most of us) who see others riding bicycles long before climbing on one ourselves.
In robotics we are very interested in both kinds of learning, and methods for programming robots that can learn are well known. A method for individual learning is called reinforcement learning (RL). It’s a laborious process in which the robot tries out lots and lots of actions and gets feedback on whether each action helps or hinders the robot in getting closer to its goal – actions that help/hinder are re/de-inforced so the robot is more/less likely to try them again; it’s a bit like shouting “warm, hot, cold, colder…” in a hide-and-seek game. It’s fair to say that RL in robotics is pretty slow; robots are not good individual learners, but that’s because, in general, they have no prior knowledge. As a fair comparison think of how long it would take you to learn how to make fire from first principles if you had no idea that getting something hot may, if you have the right materials and are persistent, create fire, or that rubbing things together can make them hot. Roboticists are also very interested in developing robots that can learn socially, especially by imitation. Robots that you can program by showing them what to do (called programming by demonstration) clearly have a big advantage over robots that have to be explicitly programmed for each new skill.
Within the artificial culture project PhD student (now Dr) Mehmet Erbas developed a new way of combining social learning by imitation and individual reinforcement learning, and the paper setting out the method together with results from simulation and real robots has been published in the journal Adaptive Behavior. Let me explain the experiments with real robots, and what we have learned from them.

Here’s our experiment. We have two robots – called e-pucks. The inset shows a closeup. Each robot has its own compartment and must – using individual (reinforcement) learning – learn how to navigate from the top right hand corner, to the bottom left hand corner of its compartment. Learning this way is slow, taking hours. But in this experiment the robots also have the ability to learn socially, by watching each other. Every so often one of the robots will stop its individual learning and drive itself out of its own compartment, to the small opening at the bottom left of the other compartment. There it will stop and simply watch the other robot while it is learning, for a few minutes. Using a movement imitation algorithm the watching robot will (socially) learn a fragment of what the other robot is doing, then combine this knowledge into what it is individually learning. The robot then runs back to its own compartment and resumes its individual learning. We call the combination of social and individual learning ‘imitation-enhanced learning’.
In order to test the effectiveness of our new imitation-enhanced learning algorithm we first run the experiment with the imitation turned off, so the robots learn only individually. This gives us a baseline for comparison. We then run two experiments with imitation-enhanced learning. In the first we wait until one robot has completed its individual learning, so it is an ‘expert’; the other robot then learns – using its combination of individual learning and social learning from the expert. Not surprisingly, learning this way is faster.
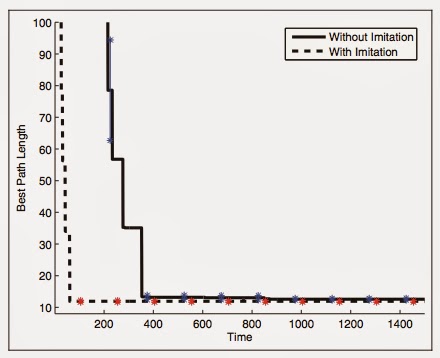
This graph shows individual learning only as the solid black line, and imitation-enhanced learning from an expert as the dashed line. In both cases learning is more or less complete when the graphs transition from vertical to horizontal. We see that individual learning takes around 360 minutes (6 hours). With the benefit of an expert to watch, learning time drops to around 60 minutes.
The second experiment is even more interesting. Here we start the two robots at the same time, so that both are equally inexpert. Now you might think it wouldn’t help at all, but remarkably each robot learns faster when it can observe, from time to time, the other inexpert robot, than when learning entirely on its own. As the graph below shows, the speedup isn’t as dramatic – but imitation enhanced learning is still faster.

Think of it this way. It’s like two novice cooks, neither of whom knows how to make chicken soup. Each is trying to figure it out by trial and error but, from time to time, they can watch each other. Even though it’s pretty likely that each will copy some things that lead to worse chicken soup, on average and over time, each hapless cook will learn how to make chicken soup a bit faster than if they were learning entirely alone.
In the paper we analyse what’s going on when one robot imitates part of the semi-learned sequence of moves by the other. And here we see something completely unexpected. Because the robots imitate each other imperfectly – when one robot watches another and then tries to copy what it saw, the copy will not be perfect – from time to time, one inexpert robot will miscopy the other inexpert robot and the miscopy, by chance, helps it to learn. To use the chicken soup analogy: it’s as if you are spying on the other cook – try to copy what they’re doing but get it wrong and, by accident, end up with better chicken soup.
This is deeply interesting because it suggests that when we learn in groups, making mistakes – noisy social learning – can actually speed up learning for each individual and for the group as a whole.
Full Reference
Mehmet D Erbas, Alan FT Winfield, and Larry Bull (2013), Embodied imitation-enhanced reinforcement learning in multi-agent systems, Adaptive Behavior. Published online 29 August 2013. Download pdf (final draft)
tags: Alan Winfield, c-Research-Innovation, EU perspectives, Learning

AUAI is supported by:









