
Robohub.org
Teaching a robot to ‘cook’ by showing it YouTube videos of cooking shows

University of Maryland computer scientist Yiannis Aloimonos (center) is developing robotic systems able to visually recognize objects and generate new behavior based on those observations.
Photo credit: John T. Consoli
Most of us have at some point watched a video in order to learn how to do something. Our research shows that a robot can learn human actions by watching videos of humans performing those actions – in this case, learning to cook by watching cooking shows on YouTube.
While it might be easy for a human to learn from watching a video, the problem is very challenging for a robot. This is because humans perform a large variety of actions that can involve various objects, body parts and movements that all have to be visually recognized by the robot, even when hands and objects might obscure parts of the video scene, as happens in the video below:
Several research groups have looked at the problem of teaching robots actions, and most have concentrated on trying to imitate or copy the actual movement. In contrast, we model them by the goals that are involved in order to accommodate the different ways manipulation actions can be performed. This introduces a set of basic constraints on the sequence of movements.
For example, if you want to cut a cucumber, first you must grasp the knife, then bring the knife to the cucumber, then perform the cutting action, and every cut separates a piece from the main cucumber. This set of rules can be expressed in the form of a context-free grammar (see Fig.1). This is a minimalist action grammar (a simple grammar with a small set of rules), and its symbols correspond to meaningful chunks of the observed video. Thus, interpreting the action in a video is like understanding a sentence that we read or hear.
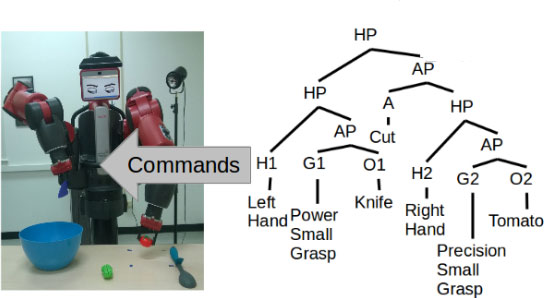
Fig.1. A grammar encodes actions by representing the underlying goals. Its symbols are the objects, tools, movements, and grasp types, which are obtained from video.
In other words, to parse the video into the primitive actions that constitute complex tasks, we need to map chunks of the video to particular symbols involving objects, tools, and movement; i.e. we need to segment the video into meaningful parts.
The paper provides a new idea that allows this segmentation of the visual data.

University of Maryland researcher Cornelia Fermuller (left) works with graduate student Yezhou Yang (right) on computer vision systems able to accurately identify and replicate intricate hand movements. Photo credit: John T. Consoli
Important locations in the video are the ones where there is contact. For example, the hand grasps the knife, or the knife touches the cucumber, and so on. These are hard to find in video, but we can predict most of them from the particular pose of the hand, i.e. the grasp type.
To address the second challenge – the visual recognition from video – we use “deep learning” techniques. We learn to recognize different grasp types (see Fig. 2), objects, and tools by learning the image information that is most relevant for the recognition. By finding the objects and the grasp type, and the times when they change in the video, we can segment and parse the video into a set of primitive actions that the robot can then execute.
In our experiments we used YouTube videos from cooking shows, and the result is that the robot “learns how to cook”. However, the approach can be generalized, and the same ideas can be used for learning other types of actions and manipulations, such as hammering or screwing, assembling, and so on.
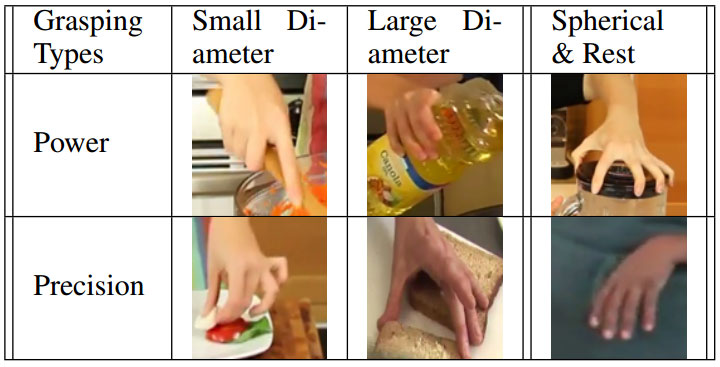
Fig.2. The different grasping types.
We are grateful to our research sponsors, specifically the MSEE DARPA Program, The European Union Cognitive Systems and Robotics Program and the NSF INSPIRE Program. The research is the result of a collaborative activity between the Computer Vision Laboratory (CVL) in the Institute for Advanced Computer Studies (UMIACS) and the Autonomy, Robotics and Cognition Laboratory (ARC) in the Institute for Systems Research, both at the University of Maryland, College Park. NICTA is funded by the Australian Government through the ICT Centre of Excellence program.
You can find a PDF of the original research paper here.
If you liked this article, you may also be interested in:
- Bipedal robot uses high-speed vision to run
- Planning robot motions that humans can relate to
- Grasping unknown objects
- Using geometry to help robots map their environment
See all the latest robotics news on Robohub, or sign up for our weekly newsletter.
tags: c-Research-Innovation, machine learning, University of Maryland






