
Robohub.org
How friendly is your AI? It depends on the rewards
by Ardi Tampuu, Tambet Matiisen, Ilya Kuzovkin, Kristjan Korjus, Jaan Aru and Raul Vicente

Two years after the small London-based startup DeepMind published their pioneering work on “Playing Atari with Deep Reinforcement Learning”, they have become one of the leaders in the chase for Artificial General Intelligence. In short, their AI learns to play video games based only on the pixel values from the screen and the reward signal. The task is quite complicated because the system has to learn to recognize objects on the screen and figure out what the goal of the game is all by itself. A more thorough peek inside their technology can be found in our previous RoboHub article. In 2015 DeepMind made their source code available online, allowing anyone to implement and explore new scenarios for Deep Reinforcement Learning – the algorithm that combines deep neural networks and reinforcement learning to guide the actions of an AI agent.
In our research group we decided to study what happens when multiple AI agents are learning in the same environment. Multiagent systems are interesting because they allow a task to be distributed among several autonomous interacting agents, similar to when a goal is to be achieved by a team of people but without any boss or captain saying what each person should do. While the decentralized nature of multi-agent systems makes them robust, flexible and easily maintained, challenges emerge in any collaboration or competition between independent agents.
There are no guarantees that Deep Reinforcement Learning algorithms can provide meaningful results when two or more autonomous agents share an environment. The goal of an agent in a reinforcement learning system is to find a strategy (policy) that yields the most rewards possible. This comes down to learning which actions are the best in each situation. For a single agent in an unchanging environment the best action in a given situation is always the same. With more than one learning agent in the same environment, however, the world is in a constant state of change. Whenever one of the agents learns something new, the other agents must adapt to this new reality and change their behaviour accordingly. When they do so, the first agent must again change itself to adapt. This means the strategies may be in constant evolution, and it is not clear whether it’s even possible to define what the “best” strategy might be.
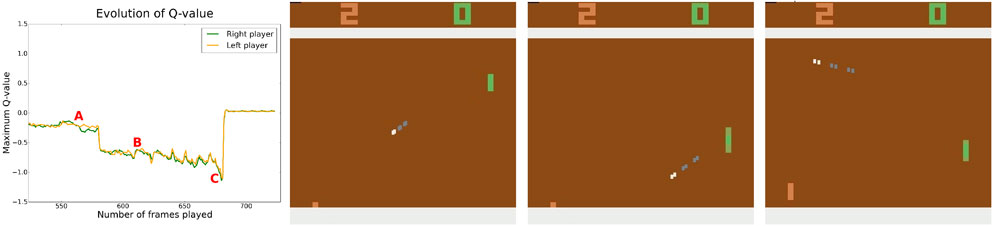
To study such scenarios, we modified DeepMind’s framework to allow two agents to share an environment and learn to either compete or collaborate. In our experiments we focused on the behaviour of the agents in well-known Pong game environment. First, we asked two AI agents to play the game against each other. Later, we changed how we rewarded the agents to promote collaboration instead of competition. We also explored the behaviour with rewarding schemes lying between competition and collaboration. To compare the emerging strategies we collected descriptions of their behaviour (e.g. how many times the players touch the ball before it goes out of play, how long they wait before serving the ball, etc …).
In the competitive mode, the two agents were rewarded for putting the ball past the opponent. As we let the agents play against each other, both of them got better and better with time. Eventually the agents learned to ward off even difficult fast-flying shots and send the ball back with speed. The behaviour at different stages of training and the final behaviour are illustrated in the video below; the graph on the right describes how highly the agents themselves evaluate the current game situation (quality or Q-value) — the higher the Q-value, the more rewards the agent expects to receive in near future.
In the collaborative game mode both agents were penalized (received negative rewards) whenever the ball went out of play. These were the only rewards the agents received. Starting from a random behaviour, agents quickly learned that the best way to avoid losing the ball is to never launch the ball in the first place. When we nevertheless forced them to serve the ball, they developed a collaborative strategy where they could keep the ball alive indefinitely. To do so they positioned themselves directly facing each other and kept the ball flying in a straight line between themselves. Note that the agents were not explicitly told what the goal was, but generated these strategies themselves as an effect of trying to avoid penalties. The learning process and the learned collaborative behaviour are illustrated by the video below:
The only difference between the above two cases was the reward an agent received for putting the ball past the opponent. In the competitive case this was rewarded positively, yielding +1 points; in the collaborative scheme this was rewarded negatively, with -1 points. We went on to explore what happens if this reward is given different values between -1 and +1. The results show that as we gradually increased the reward, the changes in behavioural descriptors were smooth. The transition from competition to collaboration seems to happen without abrupt changes.
This preliminary study of multi-agent systems using DeepMind’s AI leaves many interesting questions untouched. How rapidly can an agent switch from collaborative to competitive behaviour? What happens if one agent tries to compete and the other collaborate? Do agents learn faster when they play against an already proficient opponent (student and teacher)? How will our agents learn to behave if asked to compete or collaborate with a human player?
The future will show whether AI and humans can learn to collaborate or are destined to compete. In any case it is clear that the AI-s will always try that maximize their rewards – it is therefore our responsibility to define these rewards ethically and clearly enough to avoid costly surprises.
Our multi-agent version of DeepMind’s code and the necessary installation instructions are made public on Github and research paper is available on Arxiv. A Python implementation of the DeepMind algorithm can be found here. You can also find couple of more technical blog post on our website at Computational Neuroscience Lab in University of Tartu, Estonia.
If you liked this article, you may also be interested in:
- Artificial General Intelligence that plays Atari video games: How did DeepMind do it?
- Why robots will not be smarter than humans by 2029
- The Master Algorithm, with UW’s Pedro Domingos
- On ‘solving intelligence’, with DeepMind’s Nando de Freitas
- The economic impact of machine learning, with Baidu’s Andrew Ng
See all the latest robotics news on Robohub, or sign up for our weekly newsletter.
tags: AI, Algorithm AI-Cognition, c-Research-Innovation, DeepMind, machine learning, neural networks






AUAI is supported by:









