
Robohub.org
Artificial General Intelligence that plays Atari video games: How did DeepMind do it?
Last December, an article named “Playing Atari with Deep Reinforcement Learning” was uploaded to arXiv by employees of a small AI company called DeepMind. Two months later Google bought DeepMind for 500 million euros, and this article is almost the only thing we know about the company . Currently our team is trying to replicate their artificial mind, and in this post we describe its inner workings.
The paper describes a single system that learns to play several old video games by selecting actions based on only the screen images and the reward signal (whether the score in the game is increased or not).
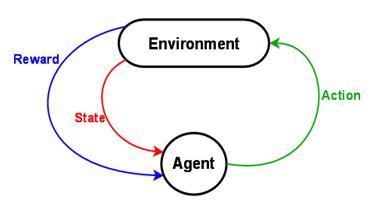
At first (before training), the program does not know anything about the game: it doesn’t know the objective of the game (if it should just stay alive, kill something or solve a puzzle), it has no understanding about its influence on the game (the consequences of its actions) and one could even say that it cannot see the objects in the game. By trial and error the system gradually learns how it should behave to receive a reward. Also note that the system uses the same architecture for all different games without any game-specific hints from the programmers other than how many possible actions there are in the game, e.g. left, right, up, down, space (fire) etc.
The reported results show that the system was able to master several games and play some of them better than a human player. This result can be seen as a step towards artificial general intelligence (AGI), which is really fascinating. Let us see in more detail how this was achieved.
The Task
The system receives a picture of the game screen (this example image is from the simplest game, Breakout) and after analyzing it, it has to choose an action to take. The action is executed and the system is told whether the score increased, decreased or did not change. Based on this information and playing a large number of games, the system needs to learn to improve its performance in the game.
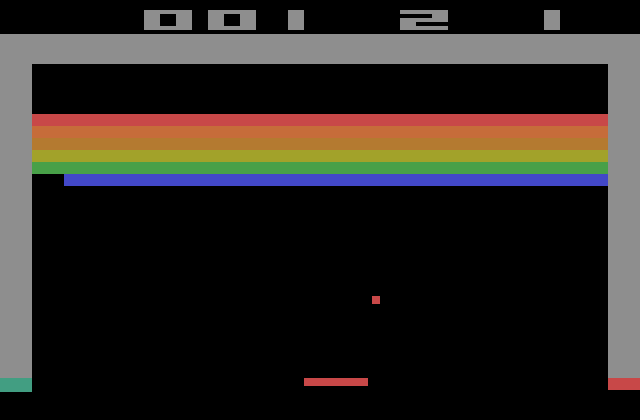
Take a pause and think about it: try to outline in your head how you would approach this task if someone had asked you to program it. Keep in mind that you do not know in advance which game your system will need to play.
Machine Learning and Artificial Neural Networks
Before we dive into the implementation DeepMind came up with, let’s introduce the concepts of machine learning and artificial neural networks.
A very common task in machine learning is: given the information about an object decide which category it belongs to. In the case of DeepMind we want to decide which action to take given the current state of the game. Machine learning algorithms learn from examples: given many example objects and their categories, the algorithm figures out which features of the object are useful for identifying the category. The algorithm produces a model that minimizes misclassification rate in the training set. This model can later be used to predict the category of an unknown object.
Artificial Neural Networks (ANN) is one of the machine learning algorithms. It is inspired by the architecture of our brain. The network consists of nodes (as our brain consists of neurons) that are connected to each other (as neurons in our brain are connected using axons, dendrites and synapses). For each neuron we must specify the condition under which the neuron should transmit the signal forward (emit a spike in real neurons). By changing the strengths of the connections one can make the network perform computation. Modern architectures of neural networks usually consist of:
- Input layer of neurons (they receive the description of an object)
- Hidden layers (the main part, where the learning happens)
- Output layer (it has one neuron for each category, the category with highest activated node is the predicted class)
After the learning is done we can feed new objects to the network and see scores for each category in the output layer.
DeepMind
In this system an ANN is used to assign an expected reward to each of the possible actions given the current game state. The network can answer a question, e.g. “How good would it be to take this action now?”. The input to the network at any time point consists of the last four game screens, so that system is given not only the last position, but also a bit of information about how the situation in the game has evolved recently. This input is then passed through three successive hidden layers of neurons and finally to the output layer of the ANN.
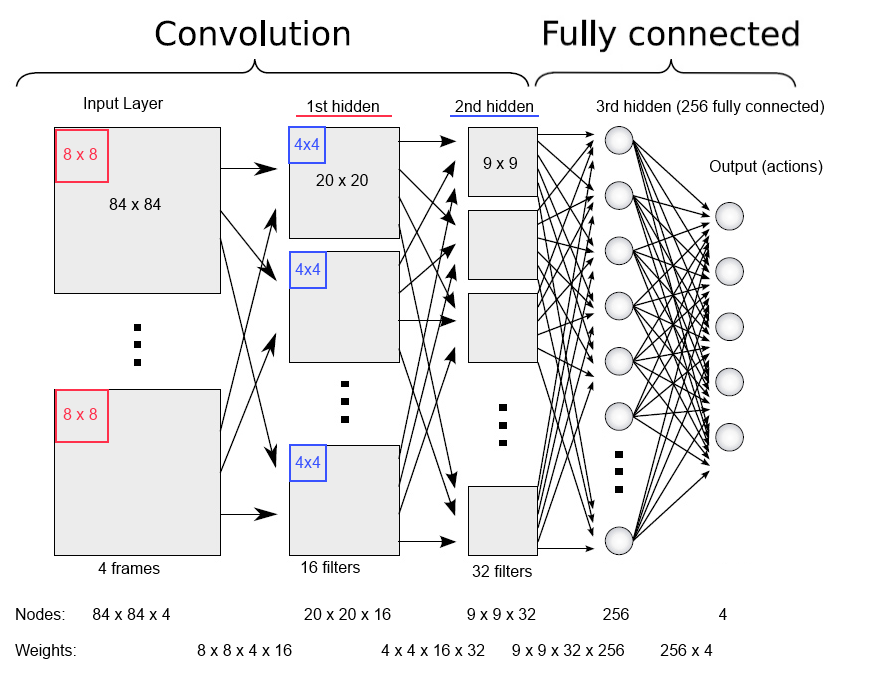
The output layer has one node for each possible action and the activation of those nodes indicates the expected reward from each of them – here, the action with the highest expected reward (the “best” action) is selected for execution. But how does the network know how to calculate the expected scores in a good and correct way?
The Learning Process
After you have defined the structure of your network there is only one thing you can still change: the strength of the connections. The learning process is, therefore, just changing the weights in a way that for all of the training examples the network is capable to propose actions that lead to positive rewards.
It is an optimisation problem where the goal is to maximize the reward over time. The problem is solved by combining gradient descent with a simple idea related to reinforcement learning: the network attempts to maximize not only the immediate reward, but also the cumulative reward of future actions. This can be achieved by estimating the expected value of the next screen image using its current neural network. To put it another way, traditionally you would use (received reward – estimated reward) as the error signal for gradient descent, but in this case we also take in consideration the reward estimate from the next image.
Summary
To summarize all the pieces we have seen, let us have one final look:
-
Build a network and initialize connections to random values
-
Feed lots and lots of game situations into the network
-
Network proposes the action to take in each of them
-
If the action was good, we reward the system, if it was bad we penalize it
-
System updates its knowledge by updating the weights
-
After several hundreds of games the system outperforms a human player (in the case of Breakout)
This result can be seen as a small step forward from the traditional machine learning in the direction of artificial general intelligence. It might be a very small step (one might say that the system does not “know” or “understand” what it is doing), but the learning capabilities of DeepMind’s system are far larger than its predecessors’ – and the range of problems is can solve without specific hints from the programmers is much wider.
Replicate and Make It Open Source
At the moment we are trying to replicate this successful project and make it available to the whole scientific community for further research. The project is open source and you can jump on board to help on Github!
References
The original paper:
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.
Our implementation at GitHub:
Reproducing the results of “Playing Atari with Deep Reinforcement Learning” by DeepMind.
The authors of this article are from the Computational Neuroscience Group at University of Tartu’s Institute of Computer Science.
If you liked this article, you may also be interested in:
- Google’s robot and artificial intelligence acquisitions are anything but scary
- Google’s DeepMind acquisition in reinforcement learning
- On internal models, consequence engines and Popperian creatures
- Why robots will not be smarter than humans by 2029
See all the latest robotics news on Robohub, or sign up for our weekly newsletter.
tags: Algorithm Controls, c-Research-Innovation, DeepMind, Google, machine learning




AUAI is supported by:









