
bots_alive Gotcha
Modern character AI could be better.
I’m unaware of any NPCs or electronic toy characters that can sustain an illusion of life over more than an hour. They suffer from predictability, simplicity, and inauthentic verbal and nonverbal behavior.
This post is about a new form of character AI. Much like motion capture for scripted animation, this new technique may revolutionize how interactive characters are created, through observation of authentic human-generated behavior.
I’ll explain via a product on which we’re pioneering this technique.
Bots_alive! A robot that plays and finds its way
We launched bots_alive last week on Kickstarter (campaign here). Here’s a 1-minute teaser video with mostly scripted motion.
The product is a smartphone kit that gives simple but lifelike autonomy to a popular RC toy, the Hexbug® Spider.
That video shows the product as we envision it at shipping time. Here you can see how it acts now, with this new character AI technique driving its core functionality already.
Training data to build a character
The character AI for these robots is created in a new way. Here’s how it works.
A human teleoperates the robot through many different scenarios. The teleoperator acts as an improvising puppeteer; he or she follows heuristics yet also empathizes with the robot and authentically responds to what happens, whether it be with curiosity, fear, jubilation, or another emotion.
For bots_alive, the teleoperator watches a screen display of what the system sees and pushes buttons to send commands of forward, back, left, right, forward-right, forward-left, back-right, or back-left. We also consider not pushing a button to be a no-action command.
From these teleoperation sessions, we gather training data containing (a) teleoperation commands and (b) information about the context in which each command was given. A category of machine learning called supervised learning is applied to create a model of the puppeteer, which effectively answers the question: In context X, what is the probability that the teleoperator would have given command Y?
Creating a behavioral model
All of that happens during development. In the end user’s hands, the robot is autonomously controlled by the model. The model of the puppeteer is the character AI.
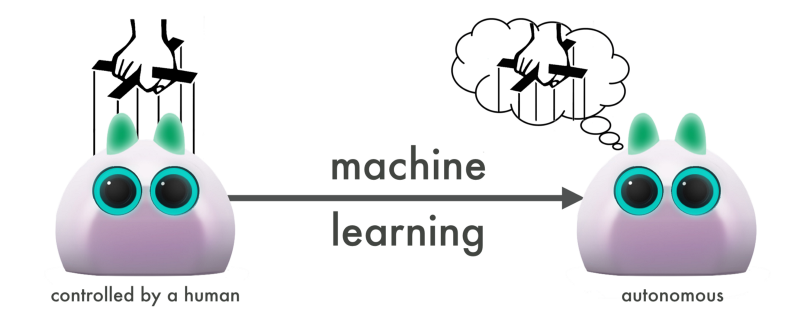 Let’s assume that the contextual information in the training data is sufficient to justify why the teleoperator chooses one action over another. Then the data contains the spontaneity, uncertainty, and social authenticity* expressed by the human puppeteer. And the autonomous robot retains these qualities if the machine learning is effective.
Let’s assume that the contextual information in the training data is sufficient to justify why the teleoperator chooses one action over another. Then the data contains the spontaneity, uncertainty, and social authenticity* expressed by the human puppeteer. And the autonomous robot retains these qualities if the machine learning is effective.
Why go to the trouble of using machine learning?
We expect this process to create character AI that feels more organic and alive than traditional character AI.
Traditional methods consist of imagining and writing rules for behavior or a finite state machine. It’s much more of an abstract exercise than immersing someone in a situation as the puppeteer.
If you play video games, imagine how much you sometimes empathize with the character you’re controlling. You may even forget the separation between the two of you, experiencing the world as that character. Consider whether your control in these moments is different, both at a high level and in tiny movements, than what the character would do if you had simply written down a set of rules for it to act by.
In that difference lies the promise of this method for developing character AI.
In psychology research methodology, there’s a broad consensus that if you want to know what someone would do in a situation, you don’t ask them what they would do. You put them in the situation and observe. Traditional character AI development is like asking the human developer or designer. Our method is instead analogous to observing a human immersed in the experience of the character. That’s why we expect it to create more authentic characters.
Our method is an application of what’s called learning from demonstration.** For times the teleoperation needs to include human interaction with the character, we keep the teleoperation secret to keep the human interaction partner from changing his or her behavior from what would be done with an autonomous character. We coined this secret version learning from the wizard (or LfW) when it was a research project at the MIT Media Lab. The name combines learning from demonstration with the Wizard of Oz experimental paradigm.
Training as interactive machine learning
In our development, I act as the teleoperator and machine learning programmer. The training process is not simply a bunch of demonstration. Rather, it’s an iterative process of:
- demonstrate
- apply machine learning on the demonstration data set
- observe behavior from the learned model
- create more demonstrations in those contexts the robot isn’t acting satisfactorily
- apply machine learning, and so on.
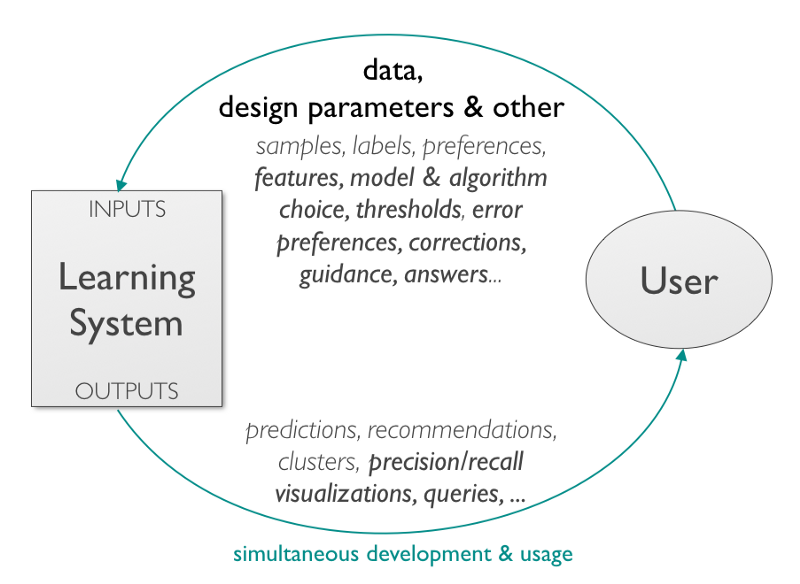
A general representation of interactive machine learning. From Amershi et al., 2015. Power to the People: The Role of Humans in Interactive Machine Learning. In AI Magazine.
Throughout these iterations, the teleoperator and algorithm designer also reflect on what contextual information still needs to be encoded to improve learning, determine what context cannot be encoded and therefore should be ignored by the teleoperator, and find fun and more delightful behavior than originally puppeteered.
How can we know that it’s better?
We can’t. Not with 100% confidence. But we have already seen that it can make compelling character AI.
We saw it in our study at MIT. In a relatively large randomized experiment, kids interacted either with a human-teleoperated robot or one with autonomous behavior learned from previous teleoperation. Compared to a no-robot condition, the teleoperated robot and the autonomous robot programmed by machine learning elicited similar behavior from their human interaction partners. Curiously, when children were asked whether the robot was human-controlled or autonomous, approximately half in each condition thought it was human-controlled. If you’re familiar with the Turing Test, the popularly known test of the effectiveness of an artificial intelligence, you might recognize that the MIT study constitutes passing a certain narrow and social Turing Test.
Compelling character AI was achieved in another such Turing test, using a technique similar to learning from demonstration, in Unreal Tournament 2004. BotPrize is a yearly academic competition for the bot that best passes as human. The 2012 winner was a bot by Jacob Schrum, Igor Karpov, and Risto Miikkulainen. It combined algorithmic optimization—which can result in markedly unnatural behavior that still achieves the specified goal— of its combat effectiveness with selective replay of recorded human behavior. Twenty-five human judges played alongside the Unreal-playing bots, repeatedly judging whether the other characters were human or artificial during combat. The bot by Schrum and colleagues was judged human more than 51.9% of the time. That percentage was just below the two human characters who were judged most human, at 53.3% and 52.2%. The algorithm is described here.
Lastly, we see compelling character AI now, in our playtesting of bots_alive.
The limitations of this approach are (1) sensing and encoding contextual information and (2) applying machine learning effectively. Both academia and industry are intensely researching how to improve those two limitations. Major strides have been made in the past 10 years, most notably through deep learning, and so it seems likely that further improvement is yet to come.
Our ability to write down behavioral rules that encode authentic behavior with an illusion of life? If there’s a reason why that will improve meaningfully, I don’t see it.
Our bots_alive robot creatures will be the first big test of this technique we call learning from the wizard.
I encourage you to get a feel for it yourself. Check out our videos of playtesting and live demos. If you’re sufficiently intrigued, pledge to our Kickstarter campaign and get one or two robots for yourself.
With robots in hand, you can judge whether they constitute a step forward in organic, believable character AI.
* Note that authentic social interaction can occur between the character AI and a human or between two of the character AIs.
** For a wonderful technical overview of learning from demonstration for robots, see this paper.
tags:
AI,
Algorithm AI-Cognition,
Algorithm Controls,
Artificial Intelligence,
c-Education-DIY,
Crowd Funding,
cx-Research-Innovation,
education,
entertainment,
gaming,
human-robot interaction,
machine learning,
Robotics technology

Brad Knox
is an AI/robotics researcher at UT and MIT. Prototyping simple robots with lifelike behavior in Austin, Texas at bots_alive.
Brad Knox
is an AI/robotics researcher at UT and MIT. Prototyping simple robots with lifelike behavior in Austin, Texas at bots_alive.










